
Python: k-Nearest Neighbors
Utilizzo l’environment conda py3
1
~$ conda activate py3
kNN
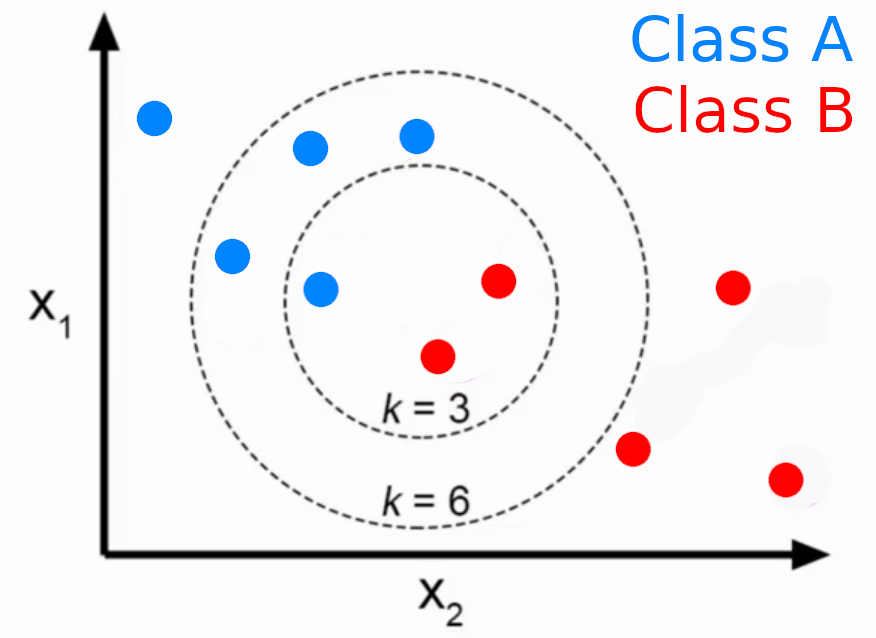
Parameters
- k
- Distance Metric
1
2
3
4
5
6
7
8
9
10
11
# lib
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report,confusion_matrix
1
2
3
# df
df = pd.read_csv("Classified Data",index_col=0)
df.head()
| WTT | PTI | EQW | SBI | LQE | QWG | FDJ | PJF | HQE | NXJ | TARGET CLASS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.913917 | 1.162073 | 0.567946 | 0.755464 | 0.780862 | 0.352608 | 0.759697 | 0.643798 | 0.879422 | 1.231409 | 1 |
| 1 | 0.635632 | 1.003722 | 0.535342 | 0.825645 | 0.924109 | 0.648450 | 0.675334 | 1.013546 | 0.621552 | 1.492702 | 0 |
| 2 | 0.721360 | 1.201493 | 0.921990 | 0.855595 | 1.526629 | 0.720781 | 1.626351 | 1.154483 | 0.957877 | 1.285597 | 0 |
| 3 | 1.234204 | 1.386726 | 0.653046 | 0.825624 | 1.142504 | 0.875128 | 1.409708 | 1.380003 | 1.522692 | 1.153093 | 1 |
| 4 | 1.279491 | 0.949750 | 0.627280 | 0.668976 | 1.232537 | 0.703727 | 1.115596 | 0.646691 | 1.463812 | 1.419167 | 1 |
Scaling data
1
2
3
4
5
6
7
8
9
10
# standardize variables per il kNN
# StandardScaler() object
scaler = StandardScaler()
# Fit scaler to the features
scaler.fit(df.drop('TARGET CLASS',axis=1))
# .transform() method to transform the features to a scaled version
scaled_features = scaler.transform(df.drop('TARGET CLASS',axis=1))
# Convert the scaled features to a dataframe
df_feat = pd.DataFrame(scaled_features,columns=df.columns[:-1])
df_feat.head()
| WTT | PTI | EQW | SBI | LQE | QWG | FDJ | PJF | HQE | NXJ | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.123542 | 0.185907 | -0.913431 | 0.319629 | -1.033637 | -2.308375 | -0.798951 | -1.482368 | -0.949719 | -0.643314 |
| 1 | -1.084836 | -0.430348 | -1.025313 | 0.625388 | -0.444847 | -1.152706 | -1.129797 | -0.202240 | -1.828051 | 0.636759 |
| 2 | -0.788702 | 0.339318 | 0.301511 | 0.755873 | 2.031693 | -0.870156 | 2.599818 | 0.285707 | -0.682494 | -0.377850 |
| 3 | 0.982841 | 1.060193 | -0.621399 | 0.625299 | 0.452820 | -0.267220 | 1.750208 | 1.066491 | 1.241325 | -1.026987 |
| 4 | 1.139275 | -0.640392 | -0.709819 | -0.057175 | 0.822886 | -0.936773 | 0.596782 | -1.472352 | 1.040772 | 0.276510 |
Training model kNN
1
2
3
4
5
6
7
# train test
X = df_feat
y = df['TARGET CLASS']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.30,random_state=101)
# X_train, X_test, y_train, y_test = train_test_split(df.drop('TARGET CLASS',axis=1),df['TARGET CLASS'],test_size=0.30,random_state=101)
1
2
3
# kNN
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
1
KNeighborsClassifier(n_neighbors=1)
1
2
# predictions
pred = knn.predict(X_test)
1
2
# confusion matrix
print(confusion_matrix(y_test,pred))
1
2
[[151 8]
[ 15 126]]
1
2
# metrics report
print(classification_report(y_test,pred))
1
2
3
4
5
6
7
8
precision recall f1-score support
0 0.91 0.95 0.93 159
1 0.94 0.89 0.92 141
accuracy 0.92 300
macro avg 0.92 0.92 0.92 300
weighted avg 0.92 0.92 0.92 300
Best k-Value Model
1
2
3
4
5
6
7
8
9
# iterate models and find best k
error_rate = []
for i in range(1,60):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
1
2
3
4
5
6
# plot trend k-errors
plt.figure(figsize=(10,6))
plt.plot(range(1,60),error_rate,color='blue',linestyle='dashed', marker='o',markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
1
Text(0, 0.5, 'Error Rate')

1
2
3
4
5
6
7
8
9
# model comparisons: k = 1
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
print('K = 1')
print('\nConfusion Matrix:')
print(confusion_matrix(y_test,pred))
print('\nClassification metrics:')
print(classification_report(y_test,pred))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
K = 1
Confusion Matrix:
[[151 8]
[ 15 126]]
Classification metrics:
precision recall f1-score support
0 0.91 0.95 0.93 159
1 0.94 0.89 0.92 141
accuracy 0.92 300
macro avg 0.92 0.92 0.92 300
weighted avg 0.92 0.92 0.92 300
1
2
3
4
5
6
7
8
9
# model comparisons: k = 40
knn = KNeighborsClassifier(n_neighbors=40)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
print('K = 40')
print('\nConfusion Matrix:')
print(confusion_matrix(y_test,pred))
print('\nClassification metrics:')
print(classification_report(y_test,pred))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
K = 40
Confusion Matrix:
[[154 5]
[ 7 134]]
Classification metrics:
precision recall f1-score support
0 0.96 0.97 0.96 159
1 0.96 0.95 0.96 141
accuracy 0.96 300
macro avg 0.96 0.96 0.96 300
weighted avg 0.96 0.96 0.96 300