Utilizzo l’environment conda py3
Versione modulo installato
1
2
3
4
5
6
7
8
9
10
11
| ~$ pip show nltk
Name: nltk
Version: 3.5
Summary: Natural Language Toolkit
Home-page: http://nltk.org/
Author: Steven Bird
Author-email: stevenbird1@gmail.com
License: Apache License, Version 2.0
Location: /home/user/miniconda3/envs/py3/lib/python3.7/site-packages
Requires: click, regex, joblib, tqdm
Required-by:
|
NLP
Il vettore contenente il conteggio delle parole è il “Bag of Words”
Per analizzarne la similarità tra i vettori è frequente utilizzare il Coseno di similitudine
\(sim\left (A,B\right )=\cos\left (\theta\right )=\frac{A\cdot B}{\left \|A \right \|\left \|B \right \|}\)
Si può migliorare il “Bag of Words” migliorando il conteggio delle parole basandosi sulla frequenza nel corpus con il TF-IDF (Term Frequency - Inverse Document Frequency).
- Term Frequency - Importanza del termine all’interno del documento
- TF(d,t) = Numero di occorrenze del termine t nel documento d
- Inverse Document Frequency - Importanza del termine all’interno del corpus
- IDF(t) = log(D/t) dove
- D = numero totale di documenti
- t = numero di documenti con il termine
\(\mathit{TF-IDF}\) del termine x all’interno del documento y
\(W_{x,y}=\mathit{tf}_{x,y}\cdot \log\left (\frac{N}{df_x}\right )\)
\(\mathit{tf}_{x,y}=\) frequenza di x in y
\(\mathit{df}_{x}=\) numero di documenti contenenti x
\(N=\) numero totale di documenti
SMS Spam Collection
UCI repository datasets
View ALL Data Sets
SMS Spam Collection Data Set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # lib
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import string
import nltk
from nltk.corpus import stopwords # bisogna scaricarlo prima, vedi sotto
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
|
1
2
3
4
5
| # scarichiamo il package delle stopwords
# nltk.download_shell()
# con l) List cerchiamo 'stopwords'
# con d) Download scarichiamo 'stopwords'
# con q) Quit si sblocca
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| NLTK Downloader
---------------------------------------------------------------------------
d) Download l) List u) Update c) Config h) Help q) Quit
---------------------------------------------------------------------------
Downloader> d
Download which package (l=list; x=cancel)?
Identifier> stopwords
Downloading package stopwords to /home/user/nltk_data...
Package stopwords is already up-to-date!
---------------------------------------------------------------------------
d) Download l) List u) Update c) Config h) Help q) Quit
---------------------------------------------------------------------------
Downloader> q
|
1
2
3
| # read data (con list comrehension per ciclare i messaggi)
messages = [line.rstrip() for line in open('SMSSpamCollection')]
print(len(messages))
|
1
2
3
| # primi 5 messaggi del corpus (collezione di testi)
messages[:5]
# \t tab separation (TSV file è come un CSV)
|
1
2
3
| ['ham\tGo until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...',
'ham\tOk lar... Joking wif u oni...',
"spam\tFree entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's"]
|
1
2
3
| # primi 5 messaggi strutturati meglio
for message_no, message in enumerate(messages[:5]):
print(message_no, "---", message)
|
1
2
3
4
5
| 0 --- ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
1 --- ham Ok lar... Joking wif u oni...
2 --- spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
3 --- ham U dun say so early hor... U c already then say...
4 --- ham Nah I don't think he goes to usf, he lives around here though
|
1
2
3
| # df
messages = pd.read_csv('SMSSpamCollection', sep='\t',names=["label", "message"])
messages.head()
|
|
label |
message |
| 0 |
ham |
Go until jurong point, crazy.. Available only ... |
| 1 |
ham |
Ok lar... Joking wif u oni... |
| 2 |
spam |
Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 |
ham |
U dun say so early hor... U c already then say... |
| 4 |
ham |
Nah I don't think he goes to usf, he lives aro... |
EDA
1
2
3
4
5
6
7
8
9
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 5572 entries, 0 to 5571
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 label 5572 non-null object
1 message 5572 non-null object
dtypes: object(2)
memory usage: 87.2+ KB
|
|
label |
message |
| count |
5572 |
5572 |
| unique |
2 |
5169 |
| top |
ham |
Sorry, I'll call later |
| freq |
4825 |
30 |
1
2
| # describe stratificato per target
messages.groupby('label').describe()
|
|
message |
|
count |
unique |
top |
freq |
| label |
|
|
|
|
| ham |
4825 |
4516 |
Sorry, I'll call later |
30 |
| spam |
747 |
653 |
Please call our customer service representativ... |
4 |
1
2
3
| # new column length messages
messages['length'] = messages['message'].apply(len)
messages.head()
|
|
label |
message |
length |
| 0 |
ham |
Go until jurong point, crazy.. Available only ... |
111 |
| 1 |
ham |
Ok lar... Joking wif u oni... |
29 |
| 2 |
spam |
Free entry in 2 a wkly comp to win FA Cup fina... |
155 |
| 3 |
ham |
U dun say so early hor... U c already then say... |
49 |
| 4 |
ham |
Nah I don't think he goes to usf, he lives aro... |
61 |
Data Visualization
1
2
3
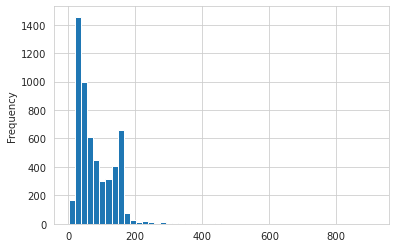
| # distribuzione lunghezza
sns.set_style('whitegrid')
messages['length'].plot(bins=50, kind='hist')
|
1
| <matplotlib.axes._subplots.AxesSubplot at 0x7fc7bb961950>
|
1
2
| # sintesi distribuzione lunghezza
messages['length'].describe()
|
1
2
3
4
5
6
7
8
9
| count 5572.000000
mean 80.489950
std 59.942907
min 2.000000
25% 36.000000
50% 62.000000
75% 122.000000
max 910.000000
Name: length, dtype: float64
|
1
2
| # estraggo l'outlier
messages[messages['length']==910]['message'].iloc[0] # printo stringa completa
|
1
| "For me the love should start with attraction.i should feel that I need her every time around me.she should be the first thing which comes in my thoughts.I would start the day and end it with her.she should be there every time I dream.love will be then when my every breath has her name.my life should happen around her.my life will be named to her.I would cry for her.will give all my happiness and take all her sorrows.I will be ready to fight with anyone for her.I will be in love when I will be doing the craziest things for her.love will be when I don't have to proove anyone that my girl is the most beautiful lady on the whole planet.I will always be singing praises for her.love will be when I start up making chicken curry and end up makiing sambar.life will be the most beautiful then.will get every morning and thank god for the day because she is with me.I would like to say a lot..will tell later.."
|
1
2
| # distribuzione lunghezza stratificato per target
messages.hist(column='length', by='label', bins=50,figsize=(12,4))
|
1
2
3
| array([<matplotlib.axes._subplots.AxesSubplot object at 0x7fc7bb2ef7d0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7fc7bb6a1790>],
dtype=object)
|

1
2
3
| # sintesi distribuzione lunghezza stratificato per target
messages.groupby('label').describe()
# i messaggi di spam sono mediamente più lunghi
|
|
length |
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
| label |
|
|
|
|
|
|
|
|
| ham |
4825.0 |
71.482487 |
58.440652 |
2.0 |
33.0 |
52.0 |
93.0 |
910.0 |
| spam |
747.0 |
138.670683 |
28.873603 |
13.0 |
133.0 |
149.0 |
157.0 |
223.0 |
Text Pre-processing
1
2
| # string.punctuation
string.punctuation
|
1
| '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
|
1
2
3
4
5
6
| # raw messages to vectors
mess = 'Sample message! Notice: it has punctuation.'
# itera ed escludi se ha punteggiatura
nopunc = [char for char in mess if char not in string.punctuation]
nopunc = ''.join(nopunc)
print(nopunc)
|
1
| Sample message Notice it has punctuation
|
1
2
| # stopwords
stopwords.words('english')[0:10] # ha anche l'italiano
|
1
| ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
|
1
2
3
| # rimuovo le stop words
clean_mess = [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
print(clean_mess)
|
1
| ['Sample', 'message', 'Notice', 'punctuation']
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # funzione per pulire
def text_process(mess):
"""
Takes in a string of text, then performs the following:
1. Remove all punctuation
2. Remove all stopwords
3. Returns a list of the cleaned text
"""
# Check characters to see if they are in punctuation
nopunc = [char for char in mess if char not in string.punctuation]
# Join the characters again to form the string.
nopunc = ''.join(nopunc)
# Now just remove any stopwords
return [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
|
|
label |
message |
| 0 |
ham |
Go until jurong point, crazy.. Available only ... |
| 1 |
ham |
Ok lar... Joking wif u oni... |
| 2 |
spam |
Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 |
ham |
U dun say so early hor... U c already then say... |
| 4 |
ham |
Nah I don't think he goes to usf, he lives aro... |
1
| messages['message'].head(5).apply(text_process)
|
1
2
3
4
5
6
| 0 [Go, jurong, point, crazy, Available, bugis, n...
1 [Ok, lar, Joking, wif, u, oni]
2 [Free, entry, 2, wkly, comp, win, FA, Cup, fin...
3 [U, dun, say, early, hor, U, c, already, say]
4 [Nah, dont, think, goes, usf, lives, around, t...
Name: message, dtype: object
|
Continuing Normalization
Si può continuare con la normalizzazione con lo stemming o con i tool di nltk.
Vectorization
Si hanno i messaggi come liste di tokens (lemmas) e bisogna convertire i messaggi in vettore tramite SciKitLearn.
Il processo avverrà in tre step usando il modello bag-of-words:
-
Conta quante volte una parola si presenta in ciascun messaggio (term frequency)
-
Pesa i conteggi, così che i token frequenti prendono peso minore (inverse document frequency)
-
Normalizza i vettori a norma unitaria, per astrarsi dalla lunghezza del testo originale (norma L2)
CountVectorizer per convertire una collezione di documenti testuali in una matrice di token counts.
Costruiamo la seguente matrice sparsa

1
2
3
4
5
| # matrix token counts
bow_transformer = CountVectorizer(analyzer=text_process).fit(messages['message'])
# total number of vocab words
print(len(bow_transformer.vocabulary_))
|
1
2
3
| # esempio: bag-of-words counts as a vector
message4 = messages['message'][3]
print(message4)
|
1
| U dun say so early hor... U c already then say...
|
1
2
3
4
| # esempio: la sua rappresentazione a vettore
bow4 = bow_transformer.transform([message4])
print(bow4)
print(bow4.shape)
|
1
2
3
4
5
6
7
8
| (0, 4068) 2
(0, 4629) 1
(0, 5261) 1
(0, 6204) 1
(0, 6222) 1
(0, 7186) 1
(0, 9554) 2
(1, 11425)
|
1
2
3
| # doppioni
print(bow_transformer.get_feature_names()[4068])
print(bow_transformer.get_feature_names()[9554])
|
1
2
3
4
| # trasformiamo tutto il corpus
messages_bow = bow_transformer.transform(messages['message'])
print('Shape of Sparse Matrix: ', messages_bow.shape)
print('Amount of Non-Zero occurences: ', messages_bow.nnz)
|
1
2
| Shape of Sparse Matrix: (5572, 11425)
Amount of Non-Zero occurences: 50548
|
1
2
3
| # sparsity (non zero vs tutti)
sparsity = (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1]))
print('sparsity: {}'.format(sparsity))
|
1
| sparsity: 0.07940295412668218
|
1
2
| # "alleno" il tf-idf su tutto il corpus in forma matriciale
tfidf_transformer = TfidfTransformer().fit(messages_bow)
|
1
2
3
| # adatto all'esempio
tfidf4 = tfidf_transformer.transform(bow4)
print(tfidf4)
|
1
2
3
4
5
6
7
| (0, 9554) 0.5385626262927564
(0, 7186) 0.4389365653379857
(0, 6222) 0.3187216892949149
(0, 6204) 0.29953799723697416
(0, 5261) 0.29729957405868723
(0, 4629) 0.26619801906087187
(0, 4068) 0.40832589933384067
|
1
2
3
| # il tf idf per due parole
print(tfidf_transformer.idf_[bow_transformer.vocabulary_['u']])
print(tfidf_transformer.idf_[bow_transformer.vocabulary_['university']])
|
1
2
| 3.2800524267409408
8.527076498901426
|
1
2
3
| # trasformiamo tutto il corpus
messages_tfidf = tfidf_transformer.transform(messages_bow)
print(messages_tfidf.shape)
|
Model: Naive Bayes
1
2
| # fit model
spam_detect_model = MultinomialNB().fit(messages_tfidf, messages['label'])
|
1
2
3
4
5
6
| print("Messaggio:")
print(message4)
print("\nForma Vettorizzata")
print(bow4)
print("\nPesi TF-IDF")
print(tfidf4)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| Messaggio:
U dun say so early hor... U c already then say...
Forma Vettorizzata
(0, 4068) 2
(0, 4629) 1
(0, 5261) 1
(0, 6204) 1
(0, 6222) 1
(0, 7186) 1
(0, 9554) 2
Pesi TF-IDF
(0, 9554) 0.5385626262927564
(0, 7186) 0.4389365653379857
(0, 6222) 0.3187216892949149
(0, 6204) 0.29953799723697416
(0, 5261) 0.29729957405868723
(0, 4629) 0.26619801906087187
(0, 4068) 0.40832589933384067
|
1
2
3
| # prediction example
print('predicted:', spam_detect_model.predict(tfidf4)[0])
print('expected:', messages.label[3])
|
1
2
| predicted: ham
expected: ham
|
1
2
3
| # predictions
all_predictions = spam_detect_model.predict(messages_tfidf)
print(all_predictions)
|
1
| ['ham' 'ham' 'spam' ... 'ham' 'ham' 'ham']
|
Pipeline
Ripetiamo l’intero processo dividendo correttamente in training e test set.
La funzione Pipeline rende tutto come una API
1
2
3
4
5
| # train test
msg_train, msg_test, label_train, label_test = \
train_test_split(messages['message'], messages['label'], test_size=0.2)
print(len(msg_train), len(msg_test), len(msg_train) + len(msg_test))
|
1
2
3
4
5
6
| # pipeline
pipeline = Pipeline([
('bow', CountVectorizer(analyzer=text_process)), # strings to token integer counts
('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores
('classifier', MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier
])
|
1
2
| # pipeline call
pipeline.fit(msg_train,label_train)
|
1
2
3
4
| Pipeline(steps=[('bow',
CountVectorizer(analyzer=<function text_process at 0x7f6fd9716ef0>)),
('tfidf', TfidfTransformer()),
('classifier', MultinomialNB())])
|
1
2
| # predictions
predictions = pipeline.predict(msg_test)
|
1
2
| # metrics
print(classification_report(predictions,label_test))
|
1
2
3
4
5
6
7
8
| precision recall f1-score support
ham 1.00 0.96 0.98 1000
spam 0.76 1.00 0.86 115
accuracy 0.97 1115
macro avg 0.88 0.98 0.92 1115
weighted avg 0.98 0.97 0.97 1115
|
Precision: how many selected items are relevant?
Recall: how many relevant items are selected?
Yelp Review Data Set
Yelp Review Data Set from Kaggle. Each observation in this dataset is a review of a particular business by a particular user.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # lib
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import string
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
|
1
2
3
| # df
yelp = pd.read_csv(r'yelp.csv')
yelp.head()
|
|
business_id |
date |
review_id |
stars |
text |
type |
user_id |
cool |
useful |
funny |
| 0 |
9yKzy9PApeiPPOUJEtnvkg |
2011-01-26 |
fWKvX83p0-ka4JS3dc6E5A |
5 |
My wife took me here on my birthday for breakf... |
review |
rLtl8ZkDX5vH5nAx9C3q5Q |
2 |
5 |
0 |
| 1 |
ZRJwVLyzEJq1VAihDhYiow |
2011-07-27 |
IjZ33sJrzXqU-0X6U8NwyA |
5 |
I have no idea why some people give bad review... |
review |
0a2KyEL0d3Yb1V6aivbIuQ |
0 |
0 |
0 |
| 2 |
6oRAC4uyJCsJl1X0WZpVSA |
2012-06-14 |
IESLBzqUCLdSzSqm0eCSxQ |
4 |
love the gyro plate. Rice is so good and I als... |
review |
0hT2KtfLiobPvh6cDC8JQg |
0 |
1 |
0 |
| 3 |
_1QQZuf4zZOyFCvXc0o6Vg |
2010-05-27 |
G-WvGaISbqqaMHlNnByodA |
5 |
Rosie, Dakota, and I LOVE Chaparral Dog Park!!... |
review |
uZetl9T0NcROGOyFfughhg |
1 |
2 |
0 |
| 4 |
6ozycU1RpktNG2-1BroVtw |
2012-01-05 |
1uJFq2r5QfJG_6ExMRCaGw |
5 |
General Manager Scott Petello is a good egg!!!... |
review |
vYmM4KTsC8ZfQBg-j5MWkw |
0 |
0 |
0 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 business_id 10000 non-null object
1 date 10000 non-null object
2 review_id 10000 non-null object
3 stars 10000 non-null int64
4 text 10000 non-null object
5 type 10000 non-null object
6 user_id 10000 non-null object
7 cool 10000 non-null int64
8 useful 10000 non-null int64
9 funny 10000 non-null int64
dtypes: int64(4), object(6)
memory usage: 781.4+ KB
|
|
stars |
cool |
useful |
funny |
| count |
10000.000000 |
10000.000000 |
10000.000000 |
10000.000000 |
| mean |
3.777500 |
0.876800 |
1.409300 |
0.701300 |
| std |
1.214636 |
2.067861 |
2.336647 |
1.907942 |
| min |
1.000000 |
0.000000 |
0.000000 |
0.000000 |
| 25% |
3.000000 |
0.000000 |
0.000000 |
0.000000 |
| 50% |
4.000000 |
0.000000 |
1.000000 |
0.000000 |
| 75% |
5.000000 |
1.000000 |
2.000000 |
1.000000 |
| max |
5.000000 |
77.000000 |
76.000000 |
57.000000 |
1
2
3
| # text length
yelp['text_length'] = yelp['text'].apply(len)
yelp['text_length'].describe()
|
1
2
3
4
5
6
7
8
9
| count 10000.000000
mean 710.738700
std 617.399827
min 1.000000
25% 294.000000
50% 541.500000
75% 930.000000
max 4997.000000
Name: text_length, dtype: float64
|
EDA
1
2
3
4
5
6
7
8
9
10
11
12
13
| # separatore migliaia come punto
import matplotlib as mpl
dot_sep = lambda x, p: format(int(x), ',').replace(",", "X").replace(".", ",").replace("X", ".")
# 5 histograms of text length based off of the star ratings
sns.set_style('whitegrid')
g = sns.FacetGrid(data=yelp,col='stars')
g.map(plt.hist,'text_length',bins=50)
for ax in g.axes[:,0]:
ax.get_yaxis().set_major_formatter(mpl.ticker.FuncFormatter(dot_sep))
ax.get_xaxis().set_major_formatter(mpl.ticker.FuncFormatter(dot_sep))
|

1
2
| # boxplot of text length for each star category
sns.boxplot(x='stars',y='text_length',data=yelp,palette='rainbow')
|
1
| <matplotlib.axes._subplots.AxesSubplot at 0x7f9cd731b090>
|

1
2
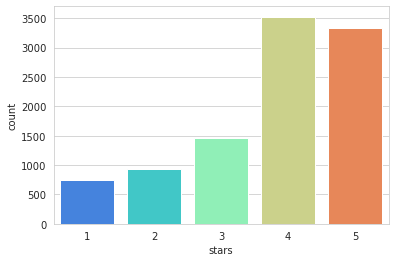
| # countplot numbere of occurrences of each type of star rating
sns.countplot(x='stars',data=yelp,palette='rainbow')
|
1
| <matplotlib.axes._subplots.AxesSubplot at 0x7f9cd731b610>
|
1
2
3
| # grouby stars mean attributes
stars = yelp.groupby(by='stars').mean()
stars
|
|
cool |
useful |
funny |
text_length |
| stars |
|
|
|
|
| 1 |
0.576769 |
1.604806 |
1.056075 |
826.515354 |
| 2 |
0.719525 |
1.563107 |
0.875944 |
842.256742 |
| 3 |
0.788501 |
1.306639 |
0.694730 |
758.498289 |
| 4 |
0.954623 |
1.395916 |
0.670448 |
712.923142 |
| 5 |
0.944261 |
1.381780 |
0.608631 |
624.999101 |
1
2
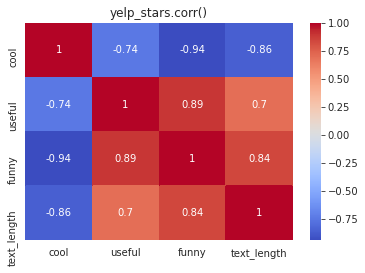
| # corr of means by stars
stars.corr()
|
|
cool |
useful |
funny |
text_length |
| cool |
1.000000 |
-0.743329 |
-0.944939 |
-0.857664 |
| useful |
-0.743329 |
1.000000 |
0.894506 |
0.699881 |
| funny |
-0.944939 |
0.894506 |
1.000000 |
0.843461 |
| text_length |
-0.857664 |
0.699881 |
0.843461 |
1.000000 |
1
2
3
| # heatmap
sns.heatmap(stars.corr(),annot=True,cmap='coolwarm')
plt.title('yelp_stars.corr()')
|
1
| Text(0.5, 1.0, 'yelp_stars.corr()')
|
NLP Classification Task
1
| yelp['stars'].value_counts()
|
1
2
3
4
5
6
| 4 3526
5 3337
3 1461
2 927
1 749
Name: stars, dtype: int64
|
1
2
3
| # only 1 and 5 rated stars
yelp_class = yelp[(yelp['stars']==1)|(yelp['stars']==5)]
yelp_class['stars'].value_counts()
|
1
2
3
| 5 3337
1 749
Name: stars, dtype: int64
|
1
2
3
| # features and target
X = yelp_class['text']
y = yelp_class['stars']
|
1
2
3
4
| # trasformo in token counts e adattiamo a tutto il corpus
X = CountVectorizer().fit_transform(X)
print('Shape of Sparse Matrix: ', X.shape)
print('Amount of Non-Zero occurences: ', X.nnz)
|
1
2
| Shape of Sparse Matrix: (4086, 19183)
Amount of Non-Zero occurences: 317288
|
Model
1
2
3
| # train test split (su matrice già in forma countvectorized)
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3, random_state=101)
|
1
2
3
| # naive bayes
nb = MultinomialNB()
nb.fit(X_train, y_train)
|
1
2
| # predictions
predictions = nb.predict(X_test)
|
1
2
3
4
5
| # confusion matrix and classification metrix
print('\nConfusion Matrix:')
print(confusion_matrix(y_test,predictions))
print('\nClassification metrics:')
print(classification_report(y_test,predictions))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| Confusion Matrix:
[[159 69]
[ 22 976]]
Classification metrics:
precision recall f1-score support
1 0.88 0.70 0.78 228
5 0.93 0.98 0.96 998
accuracy 0.93 1226
macro avg 0.91 0.84 0.87 1226
weighted avg 0.92 0.93 0.92 1226
|
Using Text Processing and Pipeline
1
2
3
4
5
| # train test split (su dati originali)
X = yelp_class['text']
y = yelp_class['stars']
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3, random_state=101)
|
1
2
3
4
5
6
| # pipeline
pipeline = Pipeline([ # lista di tuple
('bow', CountVectorizer()), # strings to token integer counts
('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores
('classifier', MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier
])
|
1
2
| # pipeline call
pipeline.fit(X_train,y_train)
|
1
2
| Pipeline(steps=[('bow', CountVectorizer()), ('tfidf', TfidfTransformer()),
('classifier', MultinomialNB())])
|
1
2
| # predictions
predictions = pipeline.predict(X_test)
|
1
2
3
4
5
| # confusion matrix and classification metrix
print('\nConfusion Matrix:')
print(confusion_matrix(y_test,predictions))
print('\nClassification metrics:')
print(classification_report(y_test,predictions))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| Confusion Matrix:
[[ 0 228]
[ 0 998]]
Classification metrics:
precision recall f1-score support
1 0.00 0.00 0.00 228
5 0.81 1.00 0.90 998
accuracy 0.81 1226
macro avg 0.41 0.50 0.45 1226
weighted avg 0.66 0.81 0.73 1226
/home/user/miniconda3/envs/py3/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1221: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
|
Risulta peggiorato con l’aggiunta del TF-IDF, si potrebbe aggiungere un custom analyzer, o direttamente rimuovere lo step del TF-IDF dalla pipeline, o cambiare il modello.
More resources
NLTK Book Online
Kaggle Walkthrough
SciKit Learn’s Tutorial
