
Statistics: Supervised Learning
La presente pagina è ricca di errori e si sconsiglia il suo utilizzo.
Se vuoi suggerire qualche modifica, puoi semplicemente proporla da GitHub
Da approfondire.
Richiami di statistica
Teorema di Gauss Markov
Proprietà stimatore LS: non distorto, tra i non distorti è quello a minima varianza…
Indipendenti e identicamente distribuiti
i.i.d. \(\Rightarrow\) scambiabilità \(\Rightarrow\) marginali identiche
Identicamente distribuiti
\(\begin{pmatrix}
X_1 \\ X_2 \\ X_3
\end{pmatrix} \sim \mathcal{N}\left(
\begin{pmatrix}
0 \\ 0 \\ 0
\end{pmatrix},
\begin{pmatrix}
1 &0 & 0 \\ 0&1&0.1 \\ 0&0.1&1
\end{pmatrix} \right)\)
Le componenti del vettore \((X_1, X_2, X_3)^T\) non sono né indipenenti, né scambiabili ma sono identicamente distribuite: le distribuzioni marginali sono tutte normali standard \(X_i\sim \mathcal{N}(0,1)\) per \(i=1,2,3\)
Scambiabili
\(\begin{pmatrix}
Y_1 \\ Y_2 \\ Y_3
\end{pmatrix} \sim \mathcal{N}\left(
\begin{pmatrix}
0 \\ 0 \\ 0
\end{pmatrix},
\begin{pmatrix}
1 &0.1 & 0.1 \\ 0.1&1&0.1 \\ 0.1&0.1&1
\end{pmatrix} \right)\)
Le componenti del vettore \((Y_1, Y_2, Y_3)^T\) non sono indipenenti ma sono scambiabili e le distribuzioni marginali sono identicamente distribuite \(Y_i\sim \mathcal{N}(0,1)\) per \(i=1,2,3\)
Modelli Lineari e Minimi Quadrati (LS)
Minimizzazione di
\(D(\beta)=\sum_{i=1}^n\big\{y_i-f(x_i; \beta)\big\}^2=\left \| y-X\beta \right \|^2=\sum_{i=1}^{n}(y_i-\hat{y})^2\) \(=y^T(I_n-P)y\)
Modello lineare multidimensionale
a più \(X\).
Sia \(y=X\beta+\epsilon\) con \(\mathbb{E}(\epsilon)=0\).
Tramite OLS (proiezione ortogonale di \(y\) su \(\mathcal{C}(X)\)):
\(\hat{y}=X\hat{\beta}=Py\)
con \(\hat{\beta}=(X^T X)^{-1}X^T y\equiv\beta+(X^T X)^{-1}X^T \epsilon\)
Inoltre,
\(\hat{\epsilon}=y-\hat{y}\) \(=y-X\hat{\beta}\)
\(\left \| \hat{\epsilon} \right \|^2\) \(=y^Ty-y^TX\hat{\beta}\)
Valore atteso dello stimatore
\(\mathbb{E}[\hat{\beta}]=\mathbb{E}[(X^TX)^{-1}X^T(X\beta+\epsilon)]=\beta\)
Varianza dello stimatore
\(\sigma^2(\hat{\beta})
=\mathbb{E}\big[ (\hat{\beta}-\mathbb{E}[\hat{\beta}])^2 \big]=\sigma^2(X^TX)^{-1}\)
Stima non distorta della varianza dello stimatore
\(\widehat{\mbox{var}}(\hat{\beta})=\frac{D(\hat{\beta})}{n-p}(X^TX)^{-1}=s^2(X^TX)^{-1}\)
\(s^2=\frac{1}{n-p}Y^T (I-P)Y=\frac{1}{n-p}\left [ Y^TY-Y^TX(X^TX)^{-1} X^T y\right ]\)
Nota: se si applica OLS con le esplicative trasformate con il logaritmo si mantiene lineare nei parametri, ma se il logaritmo si applica alla risposta non è più lineare nei parametri. La stima non è OLS e non è la migliore in termini di minimizzazione della devianza, ma mantiene la sua validità. Anche l’\(R^2\) non risulterebbe confrontabile.
Ricalcolare l’\(R^2\) retrotrasformando la previsione per il log Y, ovvero retrotrasformarla con l’esponenziale per ottenere Y.
Vantaggi disegno bilanciato: coefficienti stimabili separatamente e possibili interpretazioni dei coefficienti come variazione della risposta alla variazione unitaria di una esplicativa tenendo le altre variabili fisse.
Variabili esplicative correlate tra loro: la variabilità dei coefficienti tende a crescere e le interpretazioni diventano difficili in quanto al variare di una esplicativa varia un’altra esplicativa.
Projection Matrix
\(P\) è la matrice cappello o di proiezione \(P=X(X^TX)^{-1}X^T\).
Proprietà della projection matrix
- Matrice \(n\times n\)
- \(P^T\) \(=P\)
- \(PP\) \(=P\)
- \(\mbox{tr}(P)=\mbox{rk}(P)\) \(=p\)
Variabili qualitative: dummy e contrasti
- Parametrizzazione ad angolo: 0/1
- Parametrizzazione simmetrica: +1/-1 (la somma degli coefficienti fa 0)
- Parametrizzazione media
Altre
Modello lineare multivariato
a più \(Y\).
Sia \(Y=X\mathcal{B}+\mathcal{E}\)
con \(\mathcal{B}\) matrice di parametri \(p\) righe (numero di variabili esplicative) per \(q\) colonne (numero di variabili risposta) e
con \(\mathcal{E}\) matrice di errore \(n\) righe per \(q\) colonne, in cui si assume che ogni riga è indipendente.
\(\tilde{Y_i}\) come vettore colonna, sarebbe la i-esima riga della matrice \(Y\) messa in colonna. Per semplicità la si mette come vettore colonna e la variabile multivariata è espressa dalle righe della Y.
Stima LS: \(\hat{ \mathcal{B} }=(X^T X)^{-1}X^T Y\).
Inoltre, \(VAR\{\tilde{\mathcal{E}_i}\}=\Sigma\) e \(\hat{\Sigma}=\frac{1}{n-p}Y^T(I-P)Y\)
Stima LS
Bisogna invertire la matrice \(X^TX\) (che è simmetrica).
Gauss-Jordan
Per invertire qualsiasi matrice si può usare il metodo di Gauss-Jordan.
Fattorizzazione di Cholesky
Per invertire una matrice simmetrica, si può usare la fattorizzazione di Cholesky.
Complessità computazionale \(p^3+\frac{np^2}{2}\) e risulta molto lento con tante variabili.
Stima LS con \(n\) non troppo grande
Fattorizzazione QR
Complessità computazionale \(2np^2\) (circa il doppio di Cholesky se \(n>>p\) e uguale se \(n=p\)).
Si cerca una scomposizione \(X=QR\) per cui \(Q_{(n\times p)}\) è una matrice ortogonale (colonne ortogonali l’una con l’altra, solitamente normalizzata per cui \(Q^T Q=I\)) e \(R_{(p\times p)}\) è triangolare superiore.
\(\hat{\beta}=(X^T X)^{-1}X^T y=R^{-1} Q^T y\quad\) e \(\quad\hat{y}=QQ^T y\)
Per ottenere la matrice \(Q\) si può usare l’Algoritmo Gram-Schmidt con ortogonalizzazioni successive.
Gram-Schmidt
Proietta la risposta su uno spazio generato da vettori ortogonali tra loro.
Con due variabili esplicative \(x_1\) e \(x_2\) e la variabile risposta \(y\), la regressione di \(y\) sul vettore dei residui \(z_{x_2\sim x_1}\), determinato dalla regressione di \(x_2\) su \(x_1\), fornisce i coefficienti di regressione multipla di \(x_2\). Il vettore \(z_{x_2\sim x_1}\) è ortogonale al vettore \(x_1\).
Il coefficiente di correlazione parziale utilizza lo stesso concetto della regressione di \(x_2\) su \(x_1\).
L’algoritmo prevede tre passi:
- inizializzazione di \(x_0\) e \(z_0\) pari a \(1_n\)
- step iterativo per \(j=1,...,p-1\) in cui si stima il coefficiente \(\hat{\gamma}_{kj}\) regredendo \(x_j\) contro tutti i residui \(z_k\) stimati in precedenza \(k=0,...,j-1\), determinando \(z_j=x_j - \sum_{k=1}^{j-1} \hat{\gamma}_{kj} z_k\)
- regressione di \(y\) sul vettore dei residui \(z_{p-1}\) per ottenere \(\hat{\beta}_{p-1}\)
\(X=Z\Gamma=ZD^{-1}D\Gamma=QR\)
con \(\Gamma\) matrice triangolare alta composta da \(\hat{\gamma}_{kj}\) e \(D_{jj}=\vert\vert z_j \vert\vert\)
Stima LS con \(n\) grande
Si cerca un metodo per aggiornare le quantità base
\(W=X^T X,\qquad u=X^T y\)
e poi si inverte \(W\) mediante algoritmi per matrici simmetriche (es. Cholesky, QR).
Data una matrice di dati con \(j\) righe, si voglio stimare i coefficienti beta con i minimi quadrati.
Sia \(_{(j)}\) il riferimento di una matrice alle prime \(j\) su \(n\) osservazioni. La matrice \((X^TX)_{(j)}\) può essere vista come la stessa matrice con \(_{(j-1)}\) righe più l’ultima.
\(W=\sum_{i=1}^n \tilde{x}_i \tilde{x}_i^T,\qquad u=\sum_{i=1}^n \tilde{x}_i y_i\)
si possono scomporre in
\(W_{(j)}=W_{(j-1)}+\tilde{x}_j \tilde{x}_j^T\) e \(u_{(j)}=u_{(j-1)}+\tilde{x}_j \tilde{y}_j\) con \(j=2,...,n\)
Quindi la stima dei beta risulta
\(\hat{\beta}_{(j)}=W^{-1}_{(j)}u_{(j)}\)
Per la stima di \(s^2\)
\(s^2_{(j)}=\frac{1}{n-p}\left [ q_{(j)} - u^T_{(j)} W^T_{(j)} u_{(j)} \right ]\)
con \(q_{(j)}=Y^T_{(j)} Y_{(j)}=\sum_{i=1}^j y_i^2=q_{(j-1)}+y_j^2\)
Il metodo consente di invertire solo due matrici \(p \times p\) per la stima dei beta ad ogni \(j\), evitando di salvare in memoria la matrice \(X\).
Se si ha un numero elevato di variabili diventa oneroso, ma si estende il metodo al fine di attenuare questo problema.
Stima ricorsiva (con filtro lineare)
Il seguente metodo, consente di invertire una sola matrice \(p\times p\) all’inizio (anche la matrice identità) e poi iterativamente si aggiornano le stime.
Per invertire una matrice generica (eg. somma di due matrici) si può usare la formula di Sherman-Morrison.
\((A+bd^T)^{-1}=A^{-1}-\frac{1}{1+d^TA^{-1}b}A^{-1}bd^TA^{-1}\)
con \(d\) vettore colonna, \(d^T\) vettore riga.
In questo caso si utilizza per invertire la matrice \(W\) vista come somma della stessa più l’elemento nuovo da utilizzare per aggiornarla.
La nuova stima è ottenuta come somma della precedente stima più l’errore di previsione pesato con il guadagno del filtro.
\(\hat{\beta}_{(n+1)}=W^{-1}_{(n+1)} u_{(n+1)}=\hat{\beta}_{(n)}+k_n (y_{n+1}-\tilde{x}^T_{n+1}\hat{\beta}_{(n)})=\hat{\beta}_{(n)}+k_n e_{n+1}\)
con \(e_{n+1}\) l’errore di \(y_{n+1}\) con la stima di \(\beta\) sulle prime \(n\) osservazioni.
La stima (ricorsiva) della devianza dello stimatore dei minimi quadrati ricorsivo al passo \(_{(n+1)}\) risulta:
\(D_{n+1}(\hat{\beta}_{(n+1)})=D_{n}(\hat{\beta}_{(n)})+he^2_{n+1}\)
si determinano facilmente \(s^2_{n+1}\) e lo standard error di \(\hat{\beta}_{(n+1)}\)
Trade-off Varianza Distorsione
Errore Quadratico Medio
\(\mathbb{E}\big\{[\hat{y}-f(x')]^2\big\}\)
\(\hat{y}\) l’elemento casuale perché dipende dall \(y\)
Si cerca il valore dei parametri di regolazione (es. grado polinomio) che minimizza l’MSE.
\(MSE\left (\hat{\theta}\right )
= \mathbb{E}\left \{\left (\hat{\theta}-\theta \right)^2\right \}
= \mathbb{E}\left \{\left (\hat{\theta} \pm \mathbb{E}\left \{\hat{\theta}\right \}+\theta \right)^2\right \}= \ldots\)
\(= \mathbb{E}\left \{\left [ \hat{\theta}-\mathbb{E}\left \{\hat{\theta}\right \} \right ] ^2\right \} + \left [\mathbb{E}\left \{\hat{\theta}\right \}-\theta \right ]^2\) \(= Var(\hat{\theta})+Bias(\hat{\theta},\theta)^2\)
\(MSE\left (\hat{y}\right )
= \mathbb{E}\left \{\left ( \hat{y}-f(x') \right ) ^2\right \}
= \ldots\)
\(= \mathbb{E}\left \{\left [ \hat{y}-\mathbb{E}\left \{\hat{y}\right \} \right ] ^2\right \} + \left [ \mathbb{E}\left \{\hat{y}\right \}-f(x') \right ] ^2\) \(= Var(\hat{y})+Bias(\hat{y},f(x'))^2\)
La decomposizione dell’MSE permette di analizzare il trade off tra varianza e distorsione in funzione della complessità del modello.
Quando la complessità del modello, identiticata con \(p\), è bassa, la distorsione è alta ma la varianza bassa; quando \(p\) aumenta, la distorsione diminuisce ma la varianza aumenta. Se \(p\) cresce, il modello si adatterà meglio ai dati, ma quando \(p\) diventa troppo grande comincerà a seguire le fluttuazioni dei dati. In tal caso la varianza aumenterà senza un significativo guadagno in distorsione, provocando così il sovradattamento nei dati e comportando un eccesso di ottimismo nel valutare l’errore di previsione.
Parametri di regolazione
- Grado del polinomio
- Dimensione del sottoinsieme
- Posizione della stepwise
- Parametri di penalizzazione
- Altro
Stima e verifica
\(f(x)\) è ignoto e si può calcolare solo la varianza residua
\(\frac{1}{n}\sum_{i=1}^n\left [ \hat{y}_i - y_i \right ] ^2\)
La varianza residua overfitta se applicata su tutto il dataset, quindi divido in due parti i dati e uso una parte per la stima e uno per la verifica.
Cross Validation
Per identificare gli iper parametri, invece di fare una suddivisione tra stima (training) e verifica (validation), si suddividono i dati in \(k\) sottoinsiemi, che si stima e si verifica a rotazione, ottenendo \(k\) stime della funzione di perdita e si sceglie il parametro che la minimizza.
\(p=\text{arg}\,\min\limits_{p}\,D^*(p)=\text{arg}\,\min\limits_{p}\,\left [ \sum_{i=1}^n \left ( y_i-\hat{y}_i \right )^2 \right ]_p\)
Consente di avere anche una stima approssimativa della variabilità degli stimatori, ad esempio facendone il boxplot perché si ottengono \(k\) stime per ogni parametro. Non sarebbe possibile nella suddivisione stima-verifica.
Da implementare su R.
Metodo parsimonioso per scegliere il miglior parametro di regolazione: costurisco il grafico dell’andamento dell’parametro di regolazione vs errore di convalida incrociata, poi identifico il parametro di regolazione che minimizza, aggiungo una volta lo standard error, traccio una linea orizzontale da quel punto e scelgo come parametro di regolazione quello corrispondente al primo che si ritrova sotto la linea (metodo 1 SE).
In fine, se si vuole ottenere un modello unico dalla CV, nel caso dei modelli parametrici, si può fare una media tra i parametri.
Leave-One-Out
\(k=n\) suddividere il numero di porzioni pari al numero di righe, quindi \(n-1\) per la stima e \(1\) riga per la verifica, rotando gli insiemi.
Computazionalmente oneroso per \(n\) elevato.
Da implementare su R.
CV LOO Sherman-Morrison
Per i stimatori lineari, sfruttando la formula di Sherman-Morrison, da un solo modello completo, si ottiene l’errore di CV Leave-One-Out:
\(y_i-\hat{y}_{-i}=\frac{y_i-\hat{y}_i}{1-P_{ii}}\)
quindi l’MSE di previsione di CV risulta
\(D^*(p)=\frac{1}{n}\sum_{i=1}^n\left [ y_i - \hat{y}_{-i} \right ] ^2 = \frac{1}{n}\sum_{i=1}^n \left ( \frac{y_i-\hat{y}_i}{1-P_{ii}} \right )^2\)
Information Criterion
In alternativa, per non suddividere il dataset e contenere l’effetto dell’overfitting della varianza residua, si può penalizzare la log verosimiglianza e cercare il modello con il valore minimo. Si penalizza la log-verosimiglianza per la relazione con la chi-quadro per differenze tra log verosimiglianze di modelli annidati. Inoltre, consente di esprimere l’aggiunta di un parametro come l’incremento dei suoi gradi di libertà (cioè il valore medio) alla log verosimiglianza. Quindi si cerca una penalizzazione che sia più grande del suo valore atteso.
- AIC: \(-2\log{p(y;\hat{\theta})}+2p=\frac{\sum_{i=1}^n(y_i-x_i\hat{\beta}_p)^2}{\sigma^2}+2p\)
- Cp: \(\frac{\sum_{i=1}^n(y_i-x_i\hat{\beta}_p)^2}{\sigma^2}-n+2p\)
- AICc, BIC/SIC, HQ
Divergenza di Kullback-Leiber
AIC di Akaike è stato ottenuto sviluppando la divergenza di Kullback-Leiber.
Cerca la funzione che minimizzi la distanza tra la vera distribuzione e la stima. Si prova che è la stima di massima verosimiglianza \(\hat{\theta}_y\) il valore che la minimizza.
Riduzione della dimensionalità
I una regressione multipla, la correlazione tra variabili esplicativa comporta
- aumento varianza dei coefficienti
- interpretazioni rischiose
Tra due variabili altamente correlate, rimuovo quella che contribuisce meno alla spiegazione della risposta.
Best subset selection
Date \(p\) variabili esplicative in una regressione lineare multipla
- stimo gli \(k={p\choose i}\) modelli con \(i=0,...,p\) numero di variabili da considerare in ogni combinazione
- uso un metodo (eg. \(R^2\)) per trovare il miglior modello interno per ogni \(i\) (parametro di regolazione: dimensione del sottoinsieme)
- uso altro metodo (eg. CV) per trovare il migliore tra i \(p+1\) modelli (parametro di regolazione: numero di esplicative) Il metodo è computazionalmente oneroso.
Forward Stepwise
Dal modello con intercetta fino al modello più completo.
Per saggiare il miglioramento si può usare il test F:
\(F=\frac{\mbox{RSS}\left (\hat{\beta}^{\tiny \mbox{OLD}}\right )-\mbox{RSS}\left (\hat{\beta}^{\tiny \mbox{NEW}}\right )}{\mbox{RSS}\left (\hat{\beta}^{\tiny \mbox{NEW}}\right )/(n-s)}\)
Backward Stepwise
Dal modello completo al modello con intercetta. Generalmente seleziona un numero più maggiore di variabili rispetto la forward.
Bidirectional Stepwise
Combinazione delle due precedenti.
PCA
Analisi delle componenti principali. Effettua una rotazione delle variabili per ottenere nuove variabili ortogonali. Si effettua la scomposizione spettrale della matrice di correlazione (o di varianze e covarianze ma è influenzata dalla scala delle variabili) \(\Sigma\):
\(\Sigma \alpha_l=\lambda^2_j \alpha_l\) con \(\lambda\) autovalori.
La PCA minimizza le distanze ortogonali, è una relazione simmetrica tra le variabili, mentre la retta dei minimi quadrati minimizza le distanze verticali in cui la scelta della direzione comporta stime differenti dei parametri.
La prima componente è la più informativa ma non necessariamente è quella che spiega meglio la target.
Esistono metodi, come la Correlazione Canonica in cui si determinano le componenti anche in funzione della risposta. Altri metodi: Minimi Quadrati Parziali (Partially Square), Independent Component Analysis, Principal Curves, etc.
Da costruire su R un metodo che restituisca i coefficienti delle variabili usando la regressione sulle componenti principali scelte. Introducendo anche la CV per la scelta del numero di componenti.
Metodi di shrinkage
Regolarizzare l’equazione di stima, penalizzando la funzione di ottimizzazione dei minimi quadrati introducendo una distorsione ma riducendo la varianza. Se tutto traslato verso lo 0 l’errore quadratico medio (e assoluto) sarà più basso.
Funzionano bene anche quando \(p>n\).
Regressione ridge
Sia \(y\in\mathbb{R}^n\) vettore risposta e \(X\in\mathbb{R}^{n\times p}\) la matrice disegno.
Il problema che risolve la regressione ridge è il seguente
\(\min\limits_{\beta}\left ( y-X\beta \right )^T \left ( y-X\beta \right )\) soggetta al vincolo \(\sum_{j=1}^p \beta_j^2 \le s\) (norma in spazio L2)
in forma di Lagrange:
\(\hat{\beta}_\lambda=\text{arg}\,\min\limits_{\beta}\left \{ \left ( y-X\beta \right )^T \left ( y-X\beta \right ) + \lambda\beta^T \beta \right \}=\left (X^TX+\lambda I \right )^{-1} X^T y\)
se \(s\uparrow\Leftrightarrow \lambda \downarrow\)
se \(\lambda\rightarrow\infty \Rightarrow \hat{\beta}_\lambda\rightarrow 0\)
se \(\lambda\rightarrow 0 \Rightarrow \hat{\beta}_\lambda\rightarrow \hat{\beta}_{LS}\)
Tipicamente non si penalizza l’intercetta.
Il metodo consente di ottenere stime anche con variabili collineari.
Calcolo stimatore ridge
\(D_{\small{\mbox{ridge}}}(\beta)=(y-X\beta)^T(y-X\beta)+\lambda \beta^T\beta= \\
=(y^T-\beta^T X^T)(y-X\beta)+\beta^T\lambda I \beta= \\
=y^Ty-\beta^T X^T y-y^T X \beta+\beta^T X^T X \beta+\beta^T\lambda I \beta=*\)
nota: \((y^T_{\small{(1\times n)}} X_{\small{(n\times n)}} \beta_{\small{(n\times 1)}})=(\beta^T X^T y)\) coincide con la trasposta perché scalare
\(*=y^Ty-\beta^T X^T y-y^T X \beta+\beta^T X^T X \beta+\beta^T\lambda I \beta= \\
=y^T y -2\beta^T X^T y + \beta^T (X^T X+\lambda I)\beta\)
Posto \(\frac{\partial D_{\small{\mbox{ridge}}}(\beta)}{\partial \beta}=0\) si ha
\(-2X^T y+2(X^T X+\lambda I) \beta=0\Rightarrow \hat{\beta}_{\small{\mbox{ridge}}}=(X^TX+\lambda I)^{-1} X^T y\)
Regressione ridge generalizzata
\(\hat{\beta}_\Omega=\text{arg}\,\min\limits_{\beta}\left \{ \left ( y-X\beta \right )^T W \left ( y-X\beta \right ) + \beta^T \Omega \beta \right \}=\left (X^T W X+\Omega \right )^{-1} X^T W y\)
con \(W\) matrice dei pesi che da pesi diversi a differenti osservazioni e \(\Omega\) matrice di penalizzazione.
Spesso la regressione ridge generalizzata si trova con \(W=I_{(n\times n)}\) e \(\Omega= V \Lambda V^T\) (decomposizione spettrale).
Interpretazione Bayesiana
Nell’approccio frequentista \(\beta\) è un vettore fisso di parametri sconosciuti che si vogliono stimare, mentre nella statistica Bayesiana si può imporre una distribuzione e ottenere una qualsiasi stima usando la distribuzione a posteriori di \(\beta\).
Si assume che la matrice del disegno \(X\) sia fissata.
La stima OLS assume che la risposta \(y\) sia \(y \vert (X,\beta)\sim\mathcal{N}(X\beta, \sigma^2 I)\) con \(\sigma > 0\) costante.
Si può ipotizzare che tutti i \(\beta_j\) siano normali indipendenti con stessa varianza \(\beta\sim \mathcal{N}(0,\tau^2 I)\).
La distribuzione a posteriori di \(\beta\) risulta
\(p(\beta \vert y, X)\propto p(\beta) \cdot p(y \vert X, \beta)=\)
\(=\exp{\left \{ -\frac{1}{2\sigma^2} (y-X\beta)^T (y-X\beta)-\frac{1}{2\tau^2} \beta^T \beta \right \}}\)
il cui beta che massimizza l’a posteriori è la regressione ridge con \(\lambda=\frac{\sigma^2}{\tau^2}\).
La stima ridge è la moda (e media) a posteriori
\(\beta \vert y \sim \mathcal{N} \left \{ \left ( X^TX+\frac{\sigma^2}{\tau^2}I \right )^{-1} X^Ty, \sigma^2 \left ( X^TX+\frac{\sigma^2}{\tau^2}I \right )^{-1} \right \}\)
Relazione con PCA
Nella PCA si ruotano le \(X\), e dopo si scelgono le prime direzioni (le più variabili), per fare la regressione su \(y\). La ridge si può formulare in modo che prenda le direzioni delle componenti principali (utilizzando la SVD \(X=UDV^T\)).
\(X\hat{\beta}^{\tiny \mbox{ridge}}=X\left ( X^TX+\lambda I \right )^{-1} X^T y =M_{\lambda}y=\sum_{j=1}^p u_j k_j u_j^T y\)
con \(k_j=\frac{d_j^2}{d^2_j+\lambda}\)
\(u_j\) vettori ortogonali della \(U\)
\(k_j\) è la quantità di compressione nelle direzioni principali
\(d_j^2\) sono autovalori della matrice delle varianze e covarianze di \(X^TX\), \(d_j^2\) sono le varianze delle componenti principali. Anziché usare la regressione sulle componenti principali, in cui solitamente si considerano solo le prime componenti e le altre vengono messe a 0, qui considera tutte le componenti comprimendo quelle meno importanti.
\(\mbox{df}(\lambda)=\mbox{tr}(M_{\lambda})=\sum_{j=1}^p k_j\) misura la complessità del modello, è una funzione monotona di \(\lambda\), al crescere della complessità si raggiungono i minimi quadrati, al decrescere i coefficienti tendono a 0.
Regressione Lasso
\(\min\limits_{\beta}\left ( y-X\beta \right )^T \left ( y-X\beta \right )\) soggetta al vincolo \(\sum \vert \beta_j \vert \le s\)
in forma di Lagrange:
\(\min\limits_{\beta}\left ( y-X\beta \right )^T \left ( y-X\beta \right )+\lambda 1^T \vert \beta \vert\)
Non c’è una forma esplicita per risolvere il problema, perché il valore assoluto comporta la discontinuità della derivata prima. Bisogna usare metodi di programmazione quadratica.
Per \(s\) piccolo alcuni parametri vengono stimati a 0, quindi è anche un modo per selezionare le variabili. \(s\), parametro di compressione, è da considerare come parametro di regolazione, da scegliere ottimizzando il trade-off varianza distorsione.
La funzione da minimizzare è un paraboloide, il cui centro è la stima di massima verosimiglianza. Nel caso a due variabili, con il Lasso il vincolo è un parallelepipedo a base quadrata, che si può visualizzare come quadrato (curve di livello) perché si ragiona solo con i due coefficienti, e un cerchio nella Ridge. La soluzione con il vincolo è il punto di contatto tra il paraboloide e il vincolo. Nel Lasso, a meno di casi estremi (es 2 variabili in cui il paraboloide è perfettamente nella diagonale), uno dei due coefficienti andrà a 0.
Con variabili esplicative ortogonali, il ridge moltiplica i coefficienti ai minimi quadrati per un valore inferiore ad 1 (ruotandoli), il lasso li trasla di una costante verso lo zero.
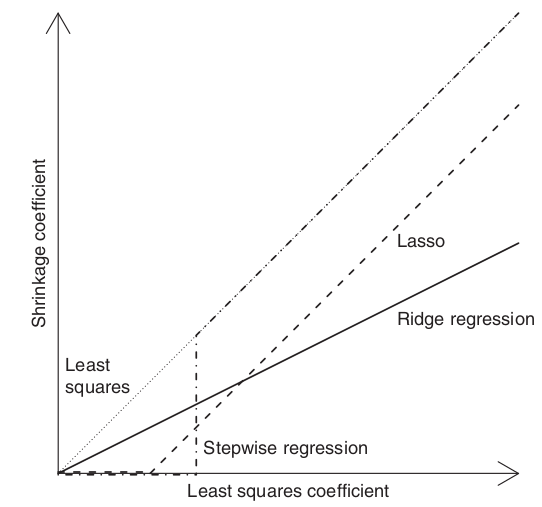
Convessità del lasso: si riferisce alla convessità della funzione di perdita quadratica.
Anche nella Ridge si ha la convessità ma è più lontana, mentre nel lasso è più vicina ad una ‘v’.
Consistenza del Lasso
La consistenza della stima MV non è garantita se lo spazio dei parametri \(p\) cresce al crescere delle osservazioni \(n\). Il Lasso è capace di identificare il modello corretto anche in questa situazione, purché le variabili esplicative veramente utili non siano troppo correlate con le variabili di disturbo altrimenti la condizione di irrepresentabilità (irrepresentable condition) o stabilità dell’intorno (neighborhod stability), viene meno. Inoltre, si assume che i coefficienti non nulli siano sufficientemente grandi.
La condizione di stabilità dell’intorno definisce che la correlazione tra le \(X\) che sono davvero uguali a zero sia molto piccola (\(1-\epsilon\)) rispetto a quella con le \(X\) che sono davvero diverse da zero.
Una procedura gode della proprietà dell’oracolo se:
- Consistenza nella selezione delle variabili: identifica le variabili veramente utili del (vero) modello
- Normalità asintotica: il tasso di stima ottimale tende a normale a media zero e covarianza del vero modello
Si dimostra che il lasso non è una procedura oracolo, invece il lasso adattivo sì.
Lasso Adattivo
Il Lasso adattivo permette di trovare una soluzione per svincolarsi dalla condizione di irrepresentabilità.
\(\hat{\beta}_{\mbox{adp}}(\lambda)=\text{arg}\,\min\limits_{\beta}\,(y-X\beta)^T(y-X\beta)+\lambda \sum_{j=1}^p\frac{\vert \beta_j \vert}{\vert \hat{\beta}_{\mbox{iniz},j} \vert}\)
La modifica della penalizzazione con lo stimatore iniziale \(\hat{\beta}_{\mbox{iniz},j}\) consente di dare maggiore peso ai parametri più importanti.
Una scelta per lo stimatore iniziale può essere la stima ai minimi quadrati orinari (o la Ridge, o i coefficienti di regressione univariata se \(p>n\), o altro).
Procedura a due step (prima si stima OLS e poi Lasso Adattivo).
Il lasso adattivo fornisce stime consistenti e mantiene la proprietà convessità propria del Lasso.
Generalizzazione del lasso adattivo
Pesando la penalizzazione \(\sum_{j=1}^p w_j \vert \beta_j \vert\)
dove \(w_j=\frac{1}{\vert \hat{\beta}_{\mbox{iniz},j} \vert^v}\) con \(v>0\)
Interpretazione Bayesiana
Come per il Ridge, se si considerano i beta (a priori) distribuiti secondo una Laplace, si ottiene lo stimatore Lasso (la densità a Posteriori ha come nucleo la forma di Lagrange dello stimatore Lasso).
Da dimostrare
Famiglia shrinkage
Il ridge e lasso possono essere casi specifici della seguente generalizzazione
\(\tilde{\beta}=\text{arg}\,\min\limits_{\beta}\,(y-X\beta)^T(y-X\beta)\) soggetta al vincolo \(\sum \vert \beta_j \vert ^q \le s\) con \(q\ge 0\).
Se \(q\le 1\) si ha la selezione delle variabili.
Ibridi
- Elastic Net
- Grouped Lasso
Least Angle Regression
LAR - Regressione con minimo angolo.
Serve a risolvere i minimi quadrati in un modo diverso ed è utile per stimare il modello Lasso.
Si inizializza il vettore dei coefficienti pari a 0, iterativamente si incrementano le stime inserendo ad una ad una le variabili più correlate con i residui che si ottengono ad ogni passo, ci si ferma fino a quando si ha correlazione minima.
LARS
Stima del Lasso con LAR
- Inizia l’algoritmo del LAR
- Se un coefficiente raggiunge lo 0 si ferma, elimina la variabile e si cerca la migliore direzione
- Si ottiene il percorso del lasso
Il LAR ha costo computazionale simile della stima LS con QR, poco più elevato perché quando si incontra lo 0 elimina e rinizia.
Pathwise cordinate descent
Con il metodo di Gauss-Newton si identifica la direzione più ripida per raggiungere il minimo. Dato che la funzione può non essere derivabile ovunque (la penalizzazione ha il modulo), invece di scendere lungo la direzione più veloce, si scende lungo le coordinate, cioè i parametri (gli assi). Si ottimizza rispetto un parametro, poi si scende verso un altro etc.
Nel Lasso il pathwise funziona perché trovare il minimo parametro per parametro si riesce velocemente.
Il minimo, per il modello Lasso, lo si ottiene tramite la stima della funzione soft-threshold:
forma estesa
\(\tilde{\beta} = \begin{cases}
\hat{\beta}+\lambda & \mbox{se } \hat{\beta}<-\lambda \\
0 & \mbox{se } -\lambda \le \hat{\beta} \le \lambda \\
\hat{\beta}-\lambda & \mbox{se } \hat{\beta} > \lambda
\end{cases}\)
forma compatta
\(\tilde{\beta}=\mbox{sign}(\hat{\beta})(\vert \hat{\beta} \vert - \lambda)_{+}\)
Per la generalizzazione con \(p\) variabili, si iterano le variabili, si calcolano i residui e si applica la soft-threshold. Può essere visto come un problema di lasso univariato dove la variabile risposta sono i residui parziali:
\(y_i-\tilde{y}_i^{(j)}=y_i-\sum_{k\ne j}x_{ik}\tilde{\beta}_k (\lambda)\)
Da approfondire
Distorsione da selezione
Sia \(\overline{X}_n-\overline{X}_N\) la differenza tra la media ottenuta nel campione con \(n\) osservazioni e la media dell’intera popolazione d’interesse.
Si può esprimere come
\(\overline{X}_n-\overline{X}_N=\sqrt{\frac{1-f}{f}}\times \sigma_X \times \rho_{R,X}\)
- \(R\) vettore di indicatrici della presenza di ciascuna unità della popolazione nel campione.
- \(f\) \(=\frac{n}{N}\)
- difficoltà del problema \(\sigma_X\): variabilità di \(X\), più è elavata e più è difficile da stimare \(\overline{X}_N\) in modo accurato
- qualità dei dati \(\rho_{R,X}\): con un buon campionamento probabilistico, quindi senza distorsione da selezione, la probabilità di osservare uno specifico valore di \(X\) non dipende dal suo valore e si avrà mediamente \(\rho_{R,X}\approx 0\).
Se si ha distorsione da selezione:
- \(Z_{n,N}=\frac{\overline{X}_n-\overline{X}_N}{\sqrt{\mbox{var}_{CCS}\overline{X}_n}}\) \(=\sqrt{N-1}\cdot \rho_{R,X}\)
- Se si vuole mantenere l’errore legato alla qualità dei dati di un ordine di grandezza confrontabile con le altre componenti dell’errore complessivo \(\rho_{R,X}\) deve essere inferiore a \(N^{1/2}\)
Metodi di regressione non parametrici
Minimizzare funzione di perdita quadrata, mediante i minimi quadrati.
Il valore che minimizza è la media condizionata delle \(y\) condizionate alle \(X\), il valore atteso condizionato cioè la funzione di regressione.
\(f(x_0)=\mathbb{E}\left \{ y \vert x=x_0 \right \}\)
Non conoscendo la vera distribuzione, se ne fa la media delle \(y\) condizionate alle \(X=x_0\).
\(f(x_0)=\mbox{Media}(y\vert x=x_0)\)
k-Nearest-Neighbor regression
\(\hat{Y}(x)=\frac{1}{k}\sum_{x_i \in N_k(x)} y_i\) con \(N_k(x)\) neighborhood o vicinato.
Si stima \(f(x_0)\) attraverso la media aritmetica delle \(y_i\) le cui \(x_i\) sono in una finestra di \(x_0\). Si determina \(\hat{f}(x_0)\) con \(k\) numero di vicini.
\(k\) unico parametro regolabile, ma i parametri sono \(N/k\) generalmente più grande di \(p\) (se le finestre non si sovrapponessero ci sarebbero \(N/k\) vicinati, con ciascuno un parametro da stimare).
Con \(k=1\) l’errore di stima è nullo.
Il metodo di mediare del k-NN con \(k=1\) è analogo alla regressione di una variabile quantitativa.
Il metodo ha alta varianza e basso bias (il contrario della regressione lineare), quindi adatto per quei contesti poco variabili.
Regressione Lineare Locale
Come il k-NN ma non effettua una media aritmetica ma una regressione lineare (regressione locale).
Sul punto generico \(x_0\) espando con Taylor:
\(f(x)=f(x_0)+f'(x_0)(x-x_0)+\mbox{resto}\)
Stimo con il metodo dei minimi quadrati pesati mediante la distanza tra \(x_i\) e \(x_0\) (si ha una forma chiusa ottenibile analiticamente):
\(\hat{\alpha},\hat{\beta}=\text{arg}\,\min\limits_{\alpha , \beta} \sum_{i=1}^n \left \{ y_i -\alpha - \beta (x_i - x_0)\right \} ^2 \omega_i\)
- \(h\) ampiezza di banda o parametro di lisciamento
- \(\omega (x_i-x_0 ;h)\) densità simmetrica attorno a \(0\), detta nucleo
Quindi si ottiene, stima esplicita e lineare nelle \(y_i\):
\(\hat{f}(x)=s_h^T y=s_{1h}y_i+ \cdots +s_{nh}y_{n}\)
\(\hat{f}(x)\) è distorto e il suo valore atteso non decresce all’aumentare di \(n\).
Per il caso multidimensionale la stima dei coefficienti sarà data da
\(\hat{\beta}=(X^T WX)^{-1} X^T Wy\)
con \(X_{(n\times p+1)}=\left \{1, (x_{1i}-x_{01}), (x_{2i}-x_{02}), (...), (x_{pi}-x_{0p})\right \}\)
e \(W_{(n\times n)}\) matrice di pesi.
Scelta del nucleo
La scelta del nucleo è meno importande dell’ampiezza di banda.
Posto
\(\omega_i=\frac{1}{h} \omega \left ( \frac{x_i - x_0}{h} \right )\)
alcune scelte possibili del nucleo \(\omega (z)\):
- Normale \(\frac{1}{\sqrt{2\pi}}\exp{\left ( -\frac{1}{2} z^2 \right )}\), dominio \(\mathbb{R}\)
- Rettangolare \(\frac{1}{2}\), dominio \((-1,1)\)
- Epanechnikov \(\frac{3}{4}(1-z^2)\) se \(\vert z \vert \le 1\) altrimenti \(0\), dominio \((-1,1)\)
- Biquadratico \(\frac{15}{16}(1-z^2)^2\) se \(\vert z \vert \le 1\) altrimenti \(0\), dominio \((-1,1)\)
- Tricubico \(\frac{70}{81}(1-\vert z \vert ^3)^3\) se \(\vert z \vert \le 1\) altrimenti \(0\), dominio \((-1,1)\)
Il nucleo a supporto limitato riduce il costo computazionale.
Scelta del parametro di lisciamento
\(\mathbb{E}\left \{ \hat{f}(x) \right \}\) \(\approx f(x) + \frac{h^2}{2}\sigma^2_{\omega} f''(x)\)
\(\mbox{var}\left \{ \hat{f}(x) \right \}\) \(\approx \frac{\sigma^2}{nh} \frac{\alpha(\omega)}{g(x)}\)
Per un \(h\) piccolo la distorsione diventa nulla, ma la varianza esplode.
Si sceglie \(h\) che minimizza l’errore quadratico medio.
Analiticamente si può esplicitare \(h\) ottimo ma questo dipende da \(f''(x)\) che a sua volta dipende da \(h\).
\(h_{\mbox{opt}}=\left ( \frac{\alpha(\omega)}{\sigma^2_\omega f''(x)^2 g(x) n} \right ) ^{1/5}\)
con \(\sigma^2_\omega=\int z^2 \omega (z) dz\), \(\alpha(\omega)=\int \omega (z)^2 dx\) e \(g(x)\) la densità da cui \(x_i\) è stato campionato. \(f''(x)\) e \(g(x)\) sono sconosciute.
L’MSE tende a \(0\) più lentamente \(O(n^{-4/5})\) dello stimatore MV \(O(n^{-1})\), la convergenza al valore vero è più lenta senza assunzioni.
LOESS
La scelta di \(h\) può essere fissa, oppure variabile in funzione della rarefazione dei punti. Determino quindi l’ampiezza di banda affinché raggiunga un numero o una percentuale prefissata di punti. Inoltre, invece di minimizzare la funzione di perdita quadratica, si minimizza l’assoluta che genera una stima più robusta agli outliers.
Curse of dimensionality
Per tutti i modelli non parametrici, al crescere della dimensione \(p\) i punti sono sempre più rarefatti.
Per mantenere costante l’errore quadratico medio (MSE) al crescere di \(p\) la numerosità campionaria deve crescere esponenzialmente.
Le assunzioni dei modelli lineari consentono di limitare il problema, quindi si cercono assunzioni non stringenti per gestire questa “maledizione’’.
\(\mbox{MSE}\approx \frac{c}{n^{4/(4+d)}}\) con \(c>0\).
Se si vuole l’MSE uguale a \(\delta\) si impone \(\mbox{MSE}=\delta\) e si risolve per \(n\Rightarrow n\propto \left ( \frac{c}{\delta}\right ) ^{d/4}\), si nota che l’MSE cresce esponenzialmente per la dimensionalità \(d\).
Distribuzione verso la frontiera
Dati \(n\) punti estratti una distribuzione uniforme \(p\)-variata, \(x\sim U^p(0,1)\), si ha che la distanza mediana dall’origine al punto più vicino, \(r(p,n)=\left ( 1-0.5^{\frac{1}{n}} \right )^{\frac{1}{p}}\), cresce molto di pù all’aumentare della dimensione che della numerosità campionaria, pertanto la maggior parte dei punti è più vicina al bordo dello spazio campionario che ad ogni altro punto.
La previsione è molto più difficile vicino ai bordi (estrapolazione contro interpolazione).
La maggior parte dei punti è vicina all’involucro convesso del campione.
L’intorno (ipercubo) contenente una frazione \(d\) di punti ha lati di lunghezza \(e_p(d)=d^{\frac{1}{p}}\). Con \(p\) dimensioni, per usare il \(d\%\) dei dati per ottenere una media ‘locale’, si dovrebbe coprire il \(e_p(d)\%\) del campo di variazione di ciascuna variabile esplicativa.
Nel caso \(p=1\), se si vuole il \(10\%\) dei dati (\(d=0.1\) frazione di punti), si prende un segmento pari al \(10\%\) della lunghezza della variabile.
Nel caso \(p=10\), se si vuole il \(10\%\) dei dati, non si prende più il \(10\%\) di ciascuna variabile, ma l’\(80\%\) (\(e_{10}(0.1)=0.80\)) di ciascuna variabile, questo perché i dati sono sparsi.
Se si vuole lo stesso ammontare di dati bisogna avere insiemi grandi, ma con insiemi grandi, gli intorni non saranno più locali ma estesi. Considerando un numero sufficiente di dati per calcolare una stima sensibile, si perde la possibilità di fare statistica non parametrica perché si considerano insiemi troppo grandi. Invece, se si considerano insiemi troppo piccoli, si avranno troppi pochi dati per stimare la statistica di riferimento.
Distanza mediana dall’origine al punto più vicino
Caso unidimensionale:
sia \(X\sim U[-1,1]\) con \(f(x)=\frac{1}{b-a}=\frac{1}{2}\) si ha che
\(F_X(m)=\mathbb{P}(X\le m)=\int_{-\infty}^m f(u)\, du=\int_{-1}^m \frac{1}{2}\, du=\frac{m+1}{2}\) quindi
la probabilità che un punto abbia distanza dall’origine inferiore a \(m\) risulta
\(\mathbb{P}(\vert X \vert \le m)=\mathbb{P}(-m\le X \le m)=\mathbb{P}(X\le m)-P(X\le -m)=m\)
questa probabilità si può anche ottenere come lo spazio favorevole \(2m\) sull’intero spazio possibile \(2\) lunghezza del segmento.
Quindi la probabilità che il punto non sia contenuto in questa distanza è \(1-m\).
Nel caso di \(n\) punti, la probabilità \(Q\) che tutti hanno una distanza dall’origine maggiore di \(m\) è \(Q=(1-m)^n\).
Si definisca \(m\) come la distanza mediana dall’origine al punto più vicino tra gli \(n\), quindi
\(Q=\frac{1}{2}\Rightarrow m=1-\left ( \frac{1}{2} \right ) ^{\frac{1}{n}}\)
Caso bidimensionale (cerchio):
sia \(X\sim U[-1,1]\) e \(Y\sim U[-1,1]\) con \(0\le X^2+X^2 \le 1\) distribuzione uniforme su un cerchio unitario con area \(\pi\) quindi con densità congiunta \(f(X,Y)=\frac{1}{\pi}\).
la probabilità che un punto abbia distanza dall’origine inferiore a \(m\) risulta
\(\mathbb{P}(R \le m)\) con \(R=\sqrt{X^2+Y^2}\)
si può determinare integrando la funzione densità sulla corona circolare di raggio \(m\) oppure ragionando in modo più semplice:
\(\mathbb{R}(R \le m)=\frac{\mbox{Area del cerchio di raggio }m}{\mbox{Area del cerchio di raggio unitario}}=\frac{\pi \cdot m^2}{\pi \cdot 1^2}=m^2\)
analogamente al caso unidimensionale, dati \(n\) punti, la probabilità \(Q\) che tutti hanno una distanza dall’origine maggiore di \(m\) è \(Q=(1-m^2)^n\).
Posto \(m\) distanza mediana dall’origine al punto più vicino tra gli \(n\) si ottiene
\(Q=\frac{1}{2}\Rightarrow m=1-\left ( \left ( \frac{1}{2} \right ) ^{\frac{1}{n}} \right ) ^{\frac{1}{2}}\)
Caso \(p\)-dimensionale (ipersfera):
\(m=r(p,n)=\left ( 1-0.5^{\frac{1}{n}} \right )^{\frac{1}{p}}\)
Splines di interpolazione
Per interpolare esattamente \(K\) punti \((\xi_k,y_k)\) per \(k=1,...,K\) detti nodi (parametro di lisciamento).
Interpolare funzioni lisce come polinomi, imponendo la continuità (di grado \(d-1\)) ai nodi.
Si richiede continuità della derivata prima (no cuspidi) e della seconda
\(f(\xi_k)=y_k\) per \(k=1,...,K\) (condizione che la funzioni passi dai nodi)
\(f(\xi_k^{-})=f(\xi_k^{+}), \quad f'(\xi_k^{-})=f'(\xi_k^{+}), \quad f''(\xi_k^{-})=f''(\xi_k^{+}), \quad\) per \(k=2,...,K-1\).
Per \(d=3\) (splines cubiche) con \(K\) nodi:
- \(4(K-1)\) parametri (\(4\) coefficienti del polinomio per \(K-1\) intervalli)
- \(K\) vincoli per interpolare i punti (deve passare dai nodi)
- \(3(K-2)\) vincoli di continuità (continuità di \(f,f',f''\) per \(K-2\) nodi interni)
- Il numero di parametri meno i vincoli precedenti rimangono 2 parametri da definire
Splines cubiche naturali: una proposta diffusa per la definizione degli ultimi 2 parametri è che la derivata seconda nei due punti estremi è nulla (andamento lineare): \(f''(\xi_1)=f''(\xi_K)=0\)
Una spline di ordine \(M\) è un polinomio a tratti di grado \(M-1\) con \(M-2\) derivate continue sui nodi. La spline cubica è una spline di ordine 4 (3 grado del polinomio più l’intercetta), è la spline di ordine più basso per il quale la discontinuità non è visibile all’occhio umano.
Quindi le spline, in condizioni di continuità sono funzioni polinomiali a tratti.
Una funzione di tipo splines si può scrivere come combinazione lineare di opportuni funzioni di base (o base di funzioni) note:
\(f(x)=\sum_{j=1}^{K+4}h_j(x)\hat{\theta}_j\)
Qualsiasi polinomiale a tratti con vincolo di continuità può essere riscritta come combinazione lineare di funzione di base.
L’insieme di funzioni di base è dato da:
\(h_j(X)=X^{j-1},\quad j=1,...,M\)
\(h_{M+\ell}(X)=(X-\xi_\ell)^{M-1}_+, \quad \ell = 1,...,K\)
con \((a)_+=\max{(a,0)}\)
Nel caso di spline cubice con 2 nodi:
\(h_1(x)=1,\quad h_2(x)=x,\quad h_3(x)=x^2,\quad h_4(x)=x^3,\quad h_5(x)=(x-\xi_1)^3_+,\quad h_6(x)=(x-\xi_2)^3_+\)
quindi la truncated power series representation è
\(f(x)=\beta_0+\beta_1 x+\beta_2 x^2+\beta_3 x^3 +\theta_1 (x-\xi_1)^3_+ + \theta_2 (x-\xi_2)^3_+\)
per definizione è una splines in quanto polinomiale a tratti, continua, con derivata I e II continua nei due nodi.
Anche le splines naturali a si possono scomporre in modo analogo ma si hanno \(K\) parametri e non più \(K+4\) (cubiche).
Splines di regressione
Regressione parametrica mediante splines - modello semi parametrico (opinione: perché si ha un numero finito di parametri e non cresce in funzione del numero delle osservazioni).
Per costruire una funzione di regressione su \(n\) punti, si divide l’asse \(x\) in \(K\) nodi e si individua una curva di tipo ‘spline cubico’ che li interpoli adeguatamente.
Stima di una spline cubica con \(K\) nodi
\(\hat{f}(x)=\sum_{j=1}^{K+4}h_j(x)\hat{\theta}_j\)
la base di funzioni è composta da \(K+4\) funzioni \(h_j(x)\) e parametri.
Per opportuni \(\theta_j\) si minimizza la devianza residua (con i minimi quadrati tradizionali) e si ottiene una spline di regressione.
Si stima una funzione parametrica con molti parametri, le splines considerabili come combinazione lineare di funzioni di base. Si possono pensare altre forme di funzione di base, come serie di fourier, seni e coseni, o le Wavelet.
La posizione dei nodi ha un’importanza minore (simile alla scelta del nucleo nella regressione locale) può essere scelta in funzione dei quantili, o equispaziati, comunque collocati dove sono presenti i dati.
La scelta del numero di nodi è impattante, da un estremo più semplice che genera un singolo polinomio al caso di \(K+1\) polinomi in cui si interpolano i dati e si genera overfitting. Va scelto con i metodi classici per identificare i parametri di regolazione ottimi.
Rendono complessa l’interpretazione rispetto LOESS e la regressione locale, ma le stime sono più stabili.
Le Splines, come la Regressione Locale, soffre molto della maledizione della dimensionalità.
Multidimensionale
Generalizzazione delle splines di regressione a più dimensioni.
Si ha una funzione di base per ogni \(x\), che si andranno a combinare mediante il loro prodotto tensoriale.
Nel caso bidimensionale \(x=(x_1,x_2)^T\in \mathbb{R}\) si hanno le seguenti basi di funzioni
\(h_{1k}(x_1)\), con \(k=1,...,K_1\) relativa alla \(x_1\),
\(h_{2k}(x_2)\), con \(k=1,...,K_2\) relativa alla \(x_2\)
La base prodotto tensoriale risulta
\(g_{jk}(x)=h_{1j}(x_1)h_{2k}(x_2)\) con \(j=1,...,K_1\) e \(k=1,...,K_2\)
Con \(K_1\) numero di funzioni di base, in questo caso 2, intercetta ed \(x\), quindi il numero di nodi è \(K_1+2?\).
Si può usare per rappresentare la funzione bidimensionale
\(g(x)=\sum_{j=1}^{K_1} \sum_{k=1}^{K_2} \theta_{jk}g_{jk}(x)\)
la stima dei \(\theta_{jk}\) viene effettuata attraverso i minimi quadrati.
Una polinomiale a tratti in \(\mathbb{R}^2\) è difficile, si costruiscono delle basi per definire una funzione che sia combinazione lineare di funzioni di base.
Si rischiano di ottenere un numero molto elevato di funzioni (4+1 per ogni nodo, e moltiplicarle per 4+1 per ogni nodo per l’altro asse), quindi si considerano le funzioni di base lineari a tratti e non cubiche. Il prodotto tensoriale di base lineari a tratti è comoda perché è nulla tranne in piccole porzioni.
Il livello di complessità è dato dal numero di nodi (\(K_1, K_2\)).
Le funzioni hanno anche le interazioni, è difficile distinguere l’effetto di ogni variabile.
Splines di lisciamento
Smoothing splines - modello parametrico.
Dato il criterio dei minimi quadrati penalizzati (nella funzione, non nei parametri come la regressione Ridge e LASSO):
\(D(f,\lambda)=\sum_{i=1}^n [y_i-f(x_i)]^2+\lambda \int_{-\infty}^{\infty}\left \{ f''(t) \right \}^2 dt\)
con \(\lambda>0\) parametro di lisciamento (più è grande più è liscia) moltiplicato per il grado di irregolarità della curva.
Si cerca \(\hat{f}_\lambda=\text{arg}\,\min\limits_{f}\,D(f,\lambda)\).
La \(f\) che minimizza la funzione di perdita risulta una spline cubica naturale:
\(f(x)=\sum_{j=1}^{n_0} N_j(x)\theta_j=N\theta\)
con \(n_0\) numero di \(x_i\) distinti e \(N_j(x)\) basi delle spline naturali (tanti nodi quante sono le osservazioni, che non è un problema grazie alla penalizzazione).
\(N\) matrice in cui la \(j\)-ma colonna contiene i valori di \(N_j\) in corrispondenza agli \(n_0\) valori distinti di \(x_i\), \(N_{ij}=N_j(x_i)\) generico elemento della matrice.
Il problema si può riscrivere come
\(\hat{\theta}_\lambda=\text{arg}\,\min\limits_{\theta\in\mathbb{R}^n}\,(y-N\theta)^T (y-N\theta)+\lambda \theta^T \Omega \theta=(N^TN+\lambda\Omega)^{-1}N^Ty\),
con \(\Omega\) matrice con elemento generico \(\Omega_{ij}=\int N_i''(t)N_j''(t)dt\).
La soluzione di ottimo è analoga alla regressione ridge generalizzata.
Sostituendo \(\hat{\theta}_\lambda\) in \(f(x)\) si ottiene \(\hat{y}=S_\lambda y\) quindi è un lisciatore lineare.
Si parla dunque di ‘smoothing splines’ o spline di lisciamento.
\(\lambda\) parametro di lisciamento stabilisce quanto è importante la penalizzazione rispetto l’aderenza ai dati. Per \(\lambda = 0\) si ottiene minimi quadrati su una funzione generica quindi genera overfitting, per \(\lambda \rightarrow \infty\) si collassa a modello di regressione lineare.
Si tratta di una tecnica che usa le splines, ma è uno strumento diverso dalle splines di regressione.
Thin plate splines
Un modo di generalizzare le smoothing splines a più dimensioni si ottiene sostituendo \(f''\) della funzione di perdita con il laplaciano (somma di tutti degli elementi dell’hessiano al quadrato).
La soluzione di ottimo risulta (non è una spline ma qualcosa di simile):
\(f(x)=\hat{\beta}_0+\hat{\beta}^T x+\sum_{j=1}^n \hat{\alpha}_j h_j(x)\)
dove \(h_j(x)=\eta\left (\vert \vert x-x_j \vert \vert \right )\) e \(\eta (z)=z^2 \log{z}\)
e \(\hat{\alpha}_j\), \(\hat{\beta}_0\) e \(\hat{\beta}\) determinati sostituendo la \(f(x)\) nell’espressione dei minimi quadrati penalizzati e minimizzando.
Sono stime non parametriche, usa i dati vicini più dei dati lontani, quindi l’operazione di estrapolazione è pericolosa, perché non si ipotizza alcuna relazione tra le \(x\) e la \(y\).
Il livello di complessità è dato da \(\lambda\).
Gradi di libertà equivalenti
Data la teoria dei modelli lineari
\(\hat{y}=Py,\qquad \hat{\epsilon}=(I-P)y\)
con l’ipotesi che \(P=X(X^TX)^{-1}X^T\) matrice simmetrica idempotente di rango \(p\) e con \(\mbox{rank}(P)=\mbox{tr}(P)=p\)
è noto che \(\mathbb{E}(\vert\vert\hat{\epsilon}\vert\vert ^2)=\sigma^2 (n-p)\) e
con l’ipotesi di normalità:
\(\vert\vert\hat{\epsilon}\vert\vert ^2\sim\sigma^2\mathcal{X}^2_{n-p}, \qquad \vert\vert\hat{y}\vert\vert ^2=\hat{y}^T\hat{y}\sim\sigma^2\mathcal{X}^2_p(\delta)\)
e \(\delta\) parametro di non centralità.
Si ricorda che:
\(\vert\vert\hat{y}\vert\vert ^2\) devianza spiegata, variabilità della regressione
\(n-p\) gradi di libertà dei residui
\(p\) gradi di libertà della regressione
\(\vert\vert y \vert\vert ^2=\vert\vert\hat{\epsilon}\vert\vert ^2+\vert\vert\hat{y}\vert\vert ^2\)
Inoltre la devianza spiegata si scompone in pezzi che dipendono da ciascuna variabile più una parte residua (ANOVA).
Fissato il parametro di regolazione, tutti i metodi visti possono essere espressi come stimatori lineari:
\(\hat{y}=S_h y\) con \(S_h\) matrice \(n\times n\)
e \(\hat{\sigma}=(I-S_h)y\)
Se si assume che l’errore \(\epsilon\) abbia distribuzione normale, \(\vert\vert\hat{\epsilon}\vert\vert ^2\) non risulta più \(\mathcal{X}^2\), ma empiricamente si assomiglia
\(\vert\vert\hat{\epsilon}\vert\vert ^2 \overset{\mbox{approx}}{\sim} \sigma^2 \mathcal{X}^2_{?}\qquad \vert\vert\hat{y}\vert\vert ^2 \overset{\mbox{approx}}{\sim} \sigma^2 \mathcal{X}^2_{??}(\delta)\)
Sia
\(Q=\sum_i \hat{\epsilon}^2_i=\vert\vert\hat{\epsilon}\vert\vert ^2=\hat{\epsilon}^T \hat{\epsilon}=y^T (I_n-S)^T(I_n-S)y\)
Poiché i gradi di libertà di una \(\mathcal{X}^2\) corrispondono al valore atteso, si determina il valore atteso di \(Q\):
\(\mathbb{E}(Q)\overset{*}{=}\mu^T(I_n-S)^T(I_n-S)\mu+\sigma^2 \mbox{tr}(I_n-S)^T(I_n-S)\)
* sfruttando la seguente proprietà di una forma quadratica:
\(\mathbb{E}\left \{ X^T AX\right \}=\mu^T A\mu+\mbox{tr}(AV)\) con \(\mu=\mathbb{E}(X)\) e \(V=\mbox{var}(X)\)
Utilizzando le approssimazioni
- \((I_n-S)\mu\) \(\approx 0\)
- \((I_n-S)^T(I_n-S)\approx (I_n-S)\) cioè idempotente
si ottiene che
\(\mathbb{E}(Q)\approx \sigma^2\{n-\mbox{tr}(S)\}\)
Quindi
\(\{n-\mbox{tr}(S)\}\) gradi di libertà equivalenti per il termine di errore
\(\mbox{tr}(S)\) gradi di libertà equivalenti per il lisciatore, ‘quanto costa di \(n\) per stimare il lisciatore’, utile per confrontare complessità di metodi differenti ma anche per fare dei test (analogia con il grado di un polinomio e i gradi di libertà, quindi numero di parametri da stimare).
Esistono altre forme di gradi di libertà equivalenti in funzione delle approssimazioni che si scelgono.
La traccia di \(S\) è paragonabile alla penalizzazione \(p\) dell’AIC.
ANOVA approssimato
Consente di costruire statistiche tipo \(F\) per valutare bontà del modello.
Test \(F\) come varianza spiegata su residua pesata per i gradi di libertà equivalenti:
\(F=\frac{\vert\vert\hat{y}-\hat{y}_0\vert\vert^2}{\hat{\sigma}^2}\frac{n-p}{nq}\sim\mathcal{F}_{\mbox{tr}(S)-\mbox{tr}(S_0),n-\mbox{tr}(S)}\)
con \(\hat{y}_0=S_0 y\) vettore dei valori adattati sotto il modello ridotto
Modelli additivi
Un modo per gestire la maledizione della dimensionalità sono i modelli additivi
\(f(x_1,...,x_p)=\alpha+\sum_{j=1}^p f_j(x_j)+\sum_{k<j} f_{kj}(x_k,x_j)+...\)
se si utilizzano tutti gli ordini di interazione si può usare per approssimare qualsiasi funzione.
Può essere una buona scelta fermarsi al termine di primo grado:
\(y=f(x_1,...,x_p)+\epsilon=\alpha+\sum_{j=1}^p f_j(x_j)+\epsilon\)
consente una maggiore libertà di forma delle variabili rispetto il modello lineare.
I modelli sono applicabili per qualsiasi numero di \(p\) rispetto ad \(n\) ma non si ottengono risultati sensati per \(p>n\).
In un contesto geografico si potrebbe aggiungere come elemento di interazione le coordinate e il resto tutte in maniera additiva.
Le \(p\) funzioni \(f_j(x_j)\) sono stimate mediante l’algoritmo ‘backfitting’.
Backfitting
È una variante dell’algoritmo di Gauss-Seidel.
Iterativamente ogni funzione si può scrivere come residui parziali, fissando tutte le altre funzioni e quindi diventando univariata:
\(f_j(x_j)=y-\left ( \alpha+\sum_{k\ne j} f_k(x_k)+\epsilon \right )\) con \(j=1,...,p\)
a questo punto si può usare un lisciatore a scelta sui residui parziali (si può usare anche uno parametrico, nel caso si usi una retta si ottengono i minimi quadrati, anche metodi diversi per variabili diverse con i corrispettivi parametri di regolazione).
Criterio di convergenza: si itera fintanto che la differenza tra la funzione nella stessa \(x\) in due step adiacenti è pressocché nulla.
Per evitare un eccesso di parametrizzazione dell’intercetta ogni funziona deve essere a media zero.
Output (su R)
L’output del modello additivo senza componenti d’interazione è generalmente composto da una parte di significatività delle variabili con il test F approssimato e una parte di grafici bidimenzionali di ciascuna variabile rispetto la target, con l’andamento delle bande di variabilità. Bisogna osservare la stima della funzione di regressione condizionata perché non vi è un solo parametro che esprime la relazione. La forma della relazione tra la target e una \(x\) è la stessa qualsiasi sia il valore delle altre \(x\). Il grafico congiunto è ottenibile dai singoli solo se si ha un modello additivo senza interazioni, un modello con interazioni è più evoluto ma non consente di commentare facilmente i singoli grafici.
Bande (intervalli) di confidenza: tengono conto della distorsione
Bande di variabilità: non tengono conto della distorsione
Nella pratica la distorsione è difficile da stimare e per semplicità spesso la si ignora quindi nella pratica le due bande coincidono.
GAM
Modelli Additivi Generalizzati. Come i GLM si usa una funzione lineare, trasformando la scala del predittore additivo nella scala della variabile risposta.
\(g\left ( \mathbb{E}\{y\vert x_1,...,x_p\} \right )=\alpha+\sum_{j=1}^p f_j(x_j)\)
Si stima con una modifica (come i minimi quadrati pesati iterati come nei GLM) dell’algoritmo di backfitting, detto punteggio locale - local scoring. Non c’è garanzia di convergenza ma l’evidenza empirica mostra risultati sensati.
Si mette insieme l’approssimazione della funzione di legame (quella dei minimi quadrati pesati iterati - IRLS) con l’iterazione del backfitting.
Il GAM permette di selezionare le variabili in modo adattiva, stimando se serve parametri a 0 (quindi escludendo le variabili inutili).
GAM con delle spline come lisciatore.
Regressione Projection Pursuit
La PPR è come un modello additivo ma su variabili rotate (ma è stata inventata prima del modello additivo). L’interpretazione è difficile.
\(f(x_i)=\sum_{m=1}^M f_m(a_m^T x_i)\)
La parte interna alla sommatoria è chiamata funzione dorsale (ridge) in \mathbb{R}. La funzione dorsale va da \(\mathbb{R}^p\) ad \(\mathbb{R}\), trasforma una combinazione lineare nello spazio delle \(y\). Si dimostra che \(M\) è sufficientemente grande allora può approssimare qualsiasi funzione nello spazio \(\mathbb{R}^p\) (ma si vuole evitare l’overfitting) - è un approssimatore universale.
Il modello additivo non è un approssimatore universale, perché ad esempio su direzioni oblique non riesce ad approssimare.
Il modello lineare non è un approssimatore universale, approssima solo iperpiani.
La PPR è invariante rispetto a trasformazioni nonsingolari delle variabili esplicative.
L’algoritmo si compone di una parte della stima degli \(a\) (sono di numerosità \(p\)) con Gauss-Newton (per ottenere l’ottimo), successivamente si itera fino a convergenza per ottenere le \(z\), si identificano passo passo le \(M\) direzioni e in fine si migliorano attraverso il backfitting.
MARS
Spline di regressione multivariate adattive. Difficili da interpretare perché tengono conto delle interazioni.
\(\eta=\beta_0+\sum_{m=1}^M \beta_m b_m (X)\)
Costruire una spline di regressione multivariata.
Nelle splines prodotto tensoriale richiedono che il modello è combinazione lineare di funzioni di base \(b\) (che vanno da \(\mathbb{R}^p\) a \(\mathbb{R}\)) come prodotti tensoriali di basi univariate in modo da costruire una base multivariata. Con \(p\) grande conviene considerare funzioni di base univariate semplici, le curve lineari a tratti, invece di considere le splines cubiche. Se le splines cubiche sono giustapposizioni di polinomio di grado 3 con vincoli di continuità e delle derivate fino al grado-1, le splines lineari non possono avere la continuità delle derivate. Nelle splines lineari l’unico vincolo è la continuità della funzione, ottenendo degli angoli. Le splines così costruite soffrono della maledizione. Le splines di regressione non sono metodi non parametrici in quanto usando le funzioni di base si stimano dei beta, quindi sono metodi parametrici, ma ne risentono della maledizione in quanto non sono effettivamente parametriche perché il numero di funzioni di base è molto grande e quindi anche il numero di parametri (dipende dai nodi) e quindi si ricade nel problema della stima con un numero elevato di parametri. Si definisce regressione semi-parametrica. Il numero di parametri da stimare dipende dal numero di funzioni di base.
Il MARS è una splines di regressione prodotto tensoriale in cui si scelgono opportunamente le funzioni di base così da limitare il problema della maledizione. Per ogni variabile si ha un numero di funzioni di base che dipende dal numero di nodi (es per una funzione abbastanza flessibile servono almeno 4-5-10 o più nodi), con il prodotto tensoriale si arrivano a considerare tutti i livelli di interazione. Approccio stepwise forward a coppie di basi, aggiungendo funzioni di base (un ‘pezzo’ di una variabile) alla volta, moltiplicata per una funzione già esistente ricostruendo la logica del prodotto tensoriale modellando le interazioni. Criterio di convergenza: inserisco quante funzioni si può e poi si eliminano (potare) con un altro metodo.
Per la potatura si può usare il metodo della stima-verifica oppure dalla CV, in cui si usano k-1 porzioni per far crescere e 1 per potatura, poi si gira e si replica k volte, ma è molto oneroso. Non si può usare la proprietà per fare la LOO in quanto le funzioni vengono scelte in modo ricorsivo e si perde la linearità, ma viene in auto la convalida incrociata generalizzata.
Si può imporre la rimozione dell’effetto principale (nodi genitori) unicamente dopo aver rimosso l’effetto di interazione.
Un modello MARS con variabili qualitative è analogo ad un modello lineare con variabili qualitative.
Il MARS seleziona le funzioni di base che entrano, usando ad esempio GCV così da controllare l’overfitting.
I modelli MARS selezionano automaticamente le variabili più influenti.
GCV
Convalida incrociata generalizzata - Generalized Cross Validation.
Quando \(\hat{y}\) ha una forma non lineare non esplicita, invece di usare ogni elemento diagonale di \(S\) si considera solo la media degli elementi diagonali, la traccia diviso per \(n\). La traccia di \(S\) è legata ai gradi di libertà. Generalizzo la CV-LOO utilizzando al numeratore gli errori residui (come sempre) e al denominatore invece della somma al quadrato di 1-elementi della diagonale di \(S\), uso 1-media degli elementi diagonali di S (cioè i gradi di libertà equivalenti) diviso \(n\). Non avendo gli elementi della diagonale e i gdl sono una misura di complessità del modello con l’assunzione di linearità, si utilizza una formulazione differente per definire la complessità.
\(\mbox{GCV}=\frac{\mbox{Errori residui}}{\left ( 1 - \frac{M}{n}\right ) ^2}=\frac{\sum_{i=1}^n(y_i-\hat{f}_\lambda(x_i))^2}{\left ( 1 - \frac{M(\lambda)}{n}\right ) ^2}\)
con
- \(\lambda\) numero di termini nel modello
- \(M\) complessità del modello (es gdl equivalenti), nel MARS è il numero di basi del modello + \(c\cdot\{\mbox{num. nodi}\}\) con \(c=2\mbox{ o }3\) definito in modo euristico.
Alberi di regressione
Classification and Regression Trees (CART).
Approssimazione a gradini di una funzione continua. Si formano più gradini dove è più ripida, meno dove è meno ripida, bisognerà decidere dove effettuare il taglio, la sua intensità e quale variabile preferire da approssimare.
\(\hat{f}(x)=\sum_{j=1}^J c_j I(x\in R_j)\)
Si sceglie la costante \(c_j\) affinché sia minima la devianza \(D\), quindi \(c_j\) è la media aritmetica degli \(y_i\) nell’intervallo.
\(R_j\) gli intervalli sono dei rettangoli con i lati paralleli agli assi.
La crescita segue una procedura passo-passo miopico in avanti. Si costruisce un albero binario con \(J\) nodi terminali (foglie) fino ad un massimo di \(J=n\) e dopo generalmente si usa un ulteriore criterio per potare.
Altri algoritmi:
- AID, CHAID usati per la classificazione
- C4.5, C5.0 sviluppati da Quinlan
Crescita
\(D=\sum_{i=1}^n \{ y_i -\hat{f}(x_i)\}^2=\sum_{j=1}^J \left \{ \sum_{i\in R_j} (y_i-\hat{c}_j)^2 \right \}=\sum_{j=1}^J D_j\)
Approccio passo passo. Allo step iniziale \(J=1,R_j=\mathbb{R}^p,D=\sum_i (y_i-M(y))^2\) si ha un solo ‘rettangolone’, successivamente si provano ‘tutte’ le possibili suddivisioni e si sceglie quella che abbassa maggiormente la devianza (max gain), provando per tutte le variabili esplicative.
gain: \(g_j=D_j - D_j^*=D_j-\left [ \sum_{i\in R'_j}(y_i-\hat{c}'_j)+ \sum_{i\in R''_j}(y_i-\hat{c}''_j) \right ]\)
Potatura
Penalizzazione della funzione di perdita
\(C_\alpha (J)=\sum_{j=1}^J D_j+\alpha J\)
L’indice di complessità \(\alpha\) è il numero di nodi dell’albero. Al crescere di \(\alpha\) si riduce l’albero e si dimostra che facendo crescere \(\alpha\) gli alberi ottimi si trovano tramite una sequenza di operazioni di potatura. Per ogni \(\alpha\) esiste un unico albero più piccolo che minimizza \(C_\alpha\).
Si seleziona la foglia la cui eliminazione comporta il minore incremento di \(\sum_j D_j\).
Scelta di \(\alpha\) e livello di potatura
Con un criterio simile ad AIC fissando \(\alpha=2\hat{\sigma}^2\), tendendo a sovra-adattarsi ai dati.
Se \(n\) è elevato, si suddivide in stima-verifica usando la parte di stima per la crescita e la verifica per la potatura, evitando di usare \(C_\alpha (J)\), usando la devianza sull’insieme di verifica.
Se \(n\) non è elevato, si può usare la CV.
I CART sono caratterizzati dalla potatura post crescita. Il CHAID ad esempio si ferma ad un certo livello della potatura. Breiman stesso suggerisce di potare anziché fermarsi prima in quanto buoni ‘split’ possono avvenire dopo una ipotetica interruzione della crescita.
La parte di stima nulla può essere generata dalla estrapolazione nelle zone senza osservazioni, quindi i risultati per quelle parti possono essere poco affidabili.
Gli alberi non sono metodi di lisciamento, non si cercano funzioni lisce.
Sono facili da interpretare se piccoli, semplici da calcolare e parallelizzare. Sono instabili: con piccole variazioni dei dati si possono ottenere alberi totalmente diversi sebbene abbiano valori simili di devianza. Non esiste un algoritmo ricorsivo per aggiornarli. Non sono adatti ad approssimare funzioni rette ripide. L’albero percepisce le interazioni, sovra-enfatizza le interazioni in quanto si condiziona ad ogni passo ai valori soglia precedenti. Non è corretto definire l’importanza delle variabili in funzione dello split, perché è valido solo il primo e gli altri sono condizionati ai precedenti.
Neural Network
Reti Neurali.
Una rete neurale è uno schema di regressione a due stadi, generalmente il tipo non lineare.
Struttura:
- variabili di input \(x_i\)
- strato invisibile (connette tutte le variabili di input e output) \(z_j\)
- variabili di output \(y_k\)
- variabile aggiuntiva per definire il livello (come l’intercetta nel modello di regressione)
\(z_j=f_0\left ( \sum_{i\rightarrow j}w_{ij}x_i\right ), \quad y_k=f_1 \left ( \sum_{j\rightarrow k} w_{jk}z_j \right )\)
con \(f_0(u)=\frac{e^u}{1+e^u}\) funzione logistica o sigmoide e \(f_1(u)=u\) identità.
Tecnicamente parametrico, ma ciascuna \(w\) ha una numerosità tale da renderlo semi-parametrico o parametrico.
Si minimizza la funzione di perdita (es. devianza) con algoritmi come il back propagation.
La Neural Network è un approssimatore universale (con un solo strato latente ed un numero elevato di nodi si può approssimare qualsiasi funzione), come la Regressione Projection Pursuit. I due metodi sono molto simili, nella NN le \(f\) sono funzioni parametriche note, nella PPR vengono stimate con un lisciatore.
Il numero di nodi nello strato latente conviene fissarlo, la CV già la si usa per l’identificazione di altri parametri.
La giusta combinazione tra strati latenti e nodi, permette di approssimare una funzione con un numero di parametri inferiore ad una rete con un solo strato latente e molti nodi (relazione quadratica tra il numero di parametri).
Backpropagation
Si minimizza una funzione di funzione
\(D=\sum_{i=1}^N\vert\vert y_i-\hat{f}(x_i)\vert\vert ^2=\sum_{i=1}^N \sum_{k=1}^K \left ( {}_{k}y_{i}-{}_{k}\hat{f}(x_i)\right )^2\)
dove
\(\hat{f}(x)=f_1\left \{ \sum_{j\rightarrow k} \beta_{jk} f_0 \left ( \sum_{h\rightarrow j} \alpha_{hj} x_h \right ) \right \}=f_1\left \{ \beta^T f_0 \left ( \alpha ^T x_h \right ) \right \}\)
con osservazione \(i\), variabile esplicativa \(h\), variabile dello strato latente \(j\) e risposta \(k\).
Si calcola la derivata (il gradiente) di una funzione di una funzione si ottiene con le derivate a catena, successivamente si cercano i minimi con un passaggio di andata e ritorno dalle \(x\) alle \(y\), così tenendo traccia delle zone locali delle \(x\).
Il gradiente coniugato è un metodo alternativo per la minimizzazione, che evita il calcolo dell’Hessiano della devianza.
Si inizializzano i coefficienti iniziali partendo da un modello lineare.
Le variabili vengono standardizzate (media sd) o normalizzate (min max) prima della stima.
Un numero ideale di unità per lo strato latente è tra le 5 e 100 unità. La scelta del numero di unità e di quali connessioni può essere determinata da una conoscenza di dominio. Ad esempio dati di immagini, si può assumere che l’unità latente dipende solo dalle zone vicine.
Teorema (cfr Ripley): una qualsiasi rete con qualsiasi numero di strati latenti può essere riscritta con un solo strato latente e un numero sufficienti di unità nello strato latente. Però utilizzare diversi strati rende più agevole la stima.
Pro:
- elevata flessibilità di variazioni
- aggiornamento sequenziale
Contro:
- tanti parametri da stimare
- instabilità di stime partendo da differenti valori inziali dei parametri (simile agli alberi)
- difficoltà interpretativa
- assenza procedure inferenziali per la significatività dei risultati
Overfitting
Per limitare sovra-adattamento si possono usare metodi come early stopping e penalizzazioni
Early stopping
Fermata anticipata
penalizzazione della devianza
Si penalizza la devianza con
\(D_0=D+\lambda J(\alpha, \beta)\)
dove \(\lambda\) di regolazione e \(J\) funzione di penalizzazione.
Scelte comuni per \(J\) sono
- penalizzazione rispetto derivata seconda (si trova nelle splines), penalizza rispetto quanto liscia è la funzione
- weight decay \(J(\alpha ,\beta)=\vert\vert\alpha\vert\vert ^2 + \vert\vert\beta\vert\vert ^2\) (come Ridge e Lasso) con \(\lambda\in (10^{-4},10^{-2})\) suggerito da Ripley
- altre
Metodi di classificazione
Classificare un’unità statistica tra i \(K\) gruppi della variabile dipendente. Ragionando in forma matriciale, in cui si considerano le \(K\) modalità osservate e le \(K\) previste, la diagonale è la corretta classificazione formata da \(K\) elementi, gli elementi fuori la diagonale \(K(K-1)\) sono i possibili modi con cui si può sbagliare, a cui si possono associare costi differenti a combinazioni di errori differenti.
Classificazione con la regressione lineare
Modello lineare su target dicotomico \({0,1}\), la previsione viene classificata in un modo se il valore è inferiore o superiore ad una soglia (es \(0.5\)).
I residui non saranno distribuiti normalmente, ma lo stimatore OLS sarà comunque BLUE (best linear unbiased estimator) purché gli errori abbiano media nulla, incorrelati e omoschedastici. Però non sarà possibile valutare tutto l’aspetto inferenziale, dagli intervalli di confidenza al p-value.
Multivariato
Nel caso di target a più classi, si creano \(K\) dummy quante sono le classi (non ci sono problemi se la matrice \(Y\) non è a rango pieno), si fa una regressione multivariata, praticamente un modello lineare per ogni classe. Per la selezione, scelgo la classe con la stima più elevata (è assimilabile al concetto di probabilità). Per \(K=2\) con due dummy prendere il massimo il risultato è analogo ad una sola target dicotomica \({0,1}\), in quanto se è superiore alla soglia di \(0.5\) e se si assume che la somma delle due variabili faccia uno, allora il massimo coincide con la previsione maggiore della soglia.
Mascheratura
Con delle separazioni di tipo lineare le curve di probabilità troppo rigide.
In più dimensioni, una classe intermedia può non essere prevista a causa della copertura che creano le stime delle variabili adiacenti. In quanto una classe intermedia sarà approssimata da un unico iperpiano piatto le cui previsioni sono meno elevate di quelle delle variabili adiacenti.
Classificazione con la regressione logistica
\(g(\pi)=\eta=\beta_0+\beta_1 x, \qquad \pi=g^{-1}(\eta)=g^{-1}(\beta_0+\beta_1 x)\)
Scelta della funzione legame \(g\) (monotona regolare)
\(g(\pi)=\log{\frac{\pi}{1-\pi}}, \qquad \pi=\frac{e^\eta}{1+e^\eta}=\frac{\exp{(\beta_0+\beta_1 x)}}{1+\exp{(\beta_0+\beta_1 x)}}\)
rispettivamente funzione logit e logistica (inverso del logit).
La stima dei \(\beta\) avviene tramite massima verosimiglianza, senza forma esplicita e si risolve numericamente (minimi quadrati iterati pesati IRLS).
Multilogit
Per \(K>2\) regressione logistica multivariata o modello multilogit.
Si creano \(K-1\) modelli di regressione logistica con il vincolo che la somma di tutte le probabilità sia uno. Tale vincolo si può ottenere facendo il logaritmo delle probabilità dei vari gruppi diviso la probabilità di un gruppo base (concetto analogo alla logistica dividendo per \(1-\pi\) che è la probabilità di essere nell’altra classe). Si può anche parametrizzare dividendo la somma di tutte le probabilità. Si otterranno \(K-1\) possibili scelte, gradi di libertà perché \(1\) è vincolato.
Si possono anche stimare \(K\) modelli non vincolando la somma delle probabilità ad \(1\).
Confusion Matrix
Tabella di errata classificazione o matrice di confusione, per un valore specifico della soglia della probabilità.
| Risposta effettiva | ||||
| Negativo | Positivo | Totale | ||
| Previsione | Negativo | $$n_{11}$$ | $$n_{12}$$ | $$n_{1\cdot}$$ |
| Positivo | $$n_{21}$$ | $$n_{22}$$ | $$n_{2\cdot}$$ | |
| Totale | $$n_{\cdot 1}$$ | $$n_{\cdot 2}$$ | $$n$$ | |
Tasso di errata classificazione (Misclassification Rate/Error Rate): \(\frac{n_{12}+n_{21}}{n}\)
complessivamente il modello quante volte sbaglia? (1-Accuratezza)
Accuratezza: \(\frac{n_{11}+n_{22}}{n}\)
complessivamente il modello quante volte classifica correttamente?
Se la soglia tende a 0, il numero di previsti negativi (\(n_{11}+n_{12}\)) tende a 0.
Al crescere della soglia, il numero di previsti negativi (\(n_{11}+n_{12}\)) tende a \(n\).
Probabilità di errore
| Risposta effettiva | |||
| Negativo | Positivo | ||
| Previsione | Negativo | $$1-\alpha$$ | $$\beta$$ |
| Positivo | $$\alpha$$ | $$1-\beta$$ | |
| Totale | 1 | 1 | |
\(\alpha\) probabilità di previsione positiva con risposta negativa, errore di primo tipo (nei test statistici si fissa \(\alpha\) e si minimizza la probabilità di rifiutare l’ipotesi nulla quando è vera)
\(\beta\) probabilità di previsione negativa con risposta positiva
Sensibilità (Sensitivity, True Positive Rate, Recall, Recupero): \(1-\hat{\beta}=\frac{n_{22}}{n_{12}+n_{22}}\)
quando la risposta è positiva, quante volte il modello prevede positivo?
Specificità (True Negative Rate): \(1-\hat{\alpha}=\frac{n_{11}}{n_{11}+n_{21}}\)
quando la risposta è negativa, quante volte il modello prevede negativo?
False Positive Rate (1-Specificità): \(\frac{n_{21}}{n_{11}+n_{21}}\)
quando la risposta è negativa, quante volte il modello prevede positivo?
Precisione (Precision): \(\frac{n_{22}}{n_{21}+n_{22}}\)
quando il modello prevede positivo, quante volte effettivamente la risposta è positiva?
False Discovery Rate: \(\frac{n_{21}}{n_{21}+n_{22}}\)
quando il modello prevede positivo, quante volte la risposta è negativa?
\(F_1\) (F-score, media armonica tra Recupero e Precisione): \(\frac{2}{1/\mbox{Recupero}+1/\mbox{Precisione}}=\frac{2n_{22}}{2n_{22}+n_{21}+n_{12}}\)
ROC Curve
Receiver Operating Characteristic.
Al variare della soglia della probabilità di classificazione, si può rappresentare l’andamento di due misure di performance.
In ascissa \(1-\)Specificità (o False Positive Rate) e in ordinata Sensibilità. \((\hat{\alpha},1-\hat{\beta})\).
AUC: Area Under the ROC Curve, è una buona misura di sintesi generica, ma per un determinato valore soglia si può potenzialmente preferire un modello con l’AUC inferiore.
Lift Curve
Fattore di miglioramento (lift): \(\frac{n_{22}}{(n_{21}+n_{22})}/\frac{(n_{12}+n_{22})}{n}=\mbox{Precisione}/\mbox{\% Positivi}\)
di quante volte migliora il modello scelto rispetto la classificazione casuale ad un dato valore specifico della soglia?
Perché la selezione casuale corrisponde alla proporzione di positivi della popolazione?
La Lift curve contiene in ordinata il fattore di miglioramento, mentre in ascissa si ha la frazione i soggetti previsti positivi ordinati in modo decrescente rispetto la probabilità di classificazione come positivo. Quindi il primo 10% di questa frazione, contiene il 10% dei dati che hanno un fattore di miglioramento più elevato rispetto la classificazione casuale. Le osservazioni sono ordinate per i valori di probabilità, se si fissa un valore soglia si può determinare il corrispettivo fattore di miglioramento e quanta popolazione si andrà a considerare.
La curva raggiunge l’1 al 100% della frazione, ma non è necessariamente monotona non crescente (se ad esempio viene fatta sull’insieme di verifica).
La curva è utile nel confronto di più modelli per capire, in funzione di una determinata % di frazione della popolazione, quale modello restituisce dei fattori di miglioramento più elevati.
Calibration Plot
Lift e ROC curve non sono appropriate per un contesto multiclasse. Un modello è utile se le probabilità previste sono ben calibrate.
Probabilità previste contro la vera proporzione di eventi, per ciascun evento. Per stimare la vera proporzione di eventi si può usare un lisciatore LOESS (ampiezza adattabile).
Analisi Discriminante
Si confrontano le densità dei gruppi per identificare delle soglie (un valore se si ha solo una esplicativa e una target dicotomica quindi con due soli gruppi, iperspazi se si lavora a più dimensioni) che li discriminano bene.
La densità marginale (complessiva) di un insieme di variabili esplicative \(p(x)\) può essere vista come una media pesata delle densità dei singoli \(K\) gruppi. Il peso è dato dalle probabilità a priori \(\pi_k\) (non necessariamente in senso bayesiano), che può essere stimato con la proporzione di osservazioni per ogni gruppo \(\hat{\pi}_k=n_k/n\) (o più in senso bayesiano con dei valori soggettivi scelti dal ricercatore in funzione di cosa si aspetta nel futuro).
Sia \(X={X_1,...,X_p}\) v.a. \(p\) dimensionale e \(Y\) variabile categoriale che definisce la \(k\)-esima classe. Si hanno \(K\) diverse funzioni densità e pesi, pertanto la densità marginale della popolazione risulta
\(p(x)=\sum_{k=1}^K \pi_k p_k (x)\)
Per ottenere la separazione più grande in termini di densità, si calcola la probabilità a posteriori
\(\mathbb{P}\{Y=k\vert X=x\}=\frac{\pi_k p_k (x)}{p(x)}\)
definisce la probabilità posteriori che una nuova unità statistica con \(X=x\) appartiene al gruppo \(k\), verrà classificata se la probabilità di un gruppo sarà maggiore dell’altra.
\(\log{\frac{\mathbb{P}\{Y=k\vert X=x\}}{\mathbb{P}\{Y=m\vert X=x\}}}=\log{\frac{\pi_k}{\pi_m}}+\log{\frac{p_k(x)}{p_m(x)}}\)
il log del rapporto è la differenza dei logaritmi, considero solo un gruppo e identifico la funzione discriminante:
\(\delta_k(x)=\log{\pi_k}+\log{p_k(x)}\)
Per stimare la densità \(p_k(x)\) si può procedere con metodi parametrici e non. Può essere vista come una funzione di regressione con il vincolo di integrazione ad 1.
Metodi di analisi discriminante: scegliere il gruppo che ha la funzione discriminante più elevata
Analisi discriminante lineare
Linear Discriminant Analysis - LDA.
Si ipotizza ciascuna \(p_k\) normale con moschedasticità, quindi \(\mathcal{N}_p(\mu_k, \Sigma)\) per \(k=1,...,K\), la funzione discriminante risulta
\(\delta_k(x)=\log{\pi_k}-\frac{1}{2}\mu_k^T\Sigma^{-1} \mu_k+x^T\Sigma^{-1}\mu_k\)
Stimati \(\mu_k\) e \(\Sigma\) usando le \(X\) (con il metodo dei momenti - le cui stime non sono robuste agli outliers: media campionaria per ogni gruppo e la varianza campionaria non distorta), la funzione discriminante è lineare nelle \(X\).
Numero di parametri da stimare: \(pK+p(p+1)/2\).
Rispetto la regressione logistica, che richiede un algoritmo iterativo, è molto più semplice computazionalmente. Anche rispetto la regressione lineare che richiede l’inversione della matrice, l’analisi discriminante lineare richiede meno calcoli ed è facilmente parallellizzabile dato che sono tutte somme.
Se le variabili esplicative sono quantitative è un approccio facilmente utilizzabile.
L’approccio funziona anche non ipotizzando l’assunzione di normalità, con assunzione di secondo ordine (solo medie e varianze), e non sarà necessario che le esplicative siano tutte continue.
Non si ha possibilità di fare selezione di variabili mediante LDA.
Analisi discriminante quadratica
Quadratic Discriminant Analysis - QDA.
Come la lineare senza l’assunzione di omoschedasticità, è necessaria l’assunzione di normalità (quindi tutte le esplicative necessariamente continue).
\(\delta_k(x)=\log{\pi_k}-\frac{1}{2}(x-\mu_k)^T\Sigma^{-1}_k (x-\mu_k)-\frac{1}{2}\log{\vert \Sigma_k \vert}\)
Con \(p\) variabili e \(K\) gruppi, si avranno \(K\) matrici \(p \times p(p+1)/2\) da stimare, ritorna il problema del tradeoff tra varianza e distorsione. Inoltre, se \(n_k\) è piccolo alcune \(\Sigma_k\) possono non essere identificabili e le stime singolari.
Non si ha un metodo automatizzabile per la selezione delle variabili.
GAM per la classificazione
Data una risposta qualitativa, si può scegliere la funzione logit come funzione legame (multilogit se qualitativa a più classi).
\(\mbox{logit}(\pi)=\alpha+\sum_{j=1}^p f_j (x_j)\)
con \(\pi\) probabilità di appartenere ad una delle due classi.
Per stimare \(f_j (x_j)\) si usa l’algoritmo del punteggio locale (local scoring, che mette assieme backfitting con minimi quadrati iterati pesati IRLS).
Si può alternativamente usare una strada quantitativa con una variabile dummy e selezionare una soglia come la regressione lineare.
MARS per classificazione
Come il MARS si può replicare la regressione con approccio quantitativo, come il modello lineare per la classificazione (e il GAM)
In alternativa, si può scegliere una log verosimiglianza multinomiale (come nei modelli parametrici), ma usando un’approssimazione quadratica per la stima (non si ottimizza la log verosimiglianza multinomiale perché bisogna iterare ed è oneroso).
Si può usare la GCV (convalida incrociata generalizzata) per ridurre il modello.
Neural Network per classificazione
Reti neurali per la classificazione.
Approccio analogo alla regressione, però la funzione di trasferimento \(f_1\) sarà un’altra trasformata logit.
Per una classificazione multiclasse si può usare la funzione logistica multidimensionale (softmax), simile alla multilogit (non è una sola classe al denominatore ma tutte le classi):
\(f_{1k}=\frac{\exp{(T_k)}}{\sum_{r=1}^K \exp{(T_r)}},\quad k=1,...,K\)
con \(T_r=\sum_{j\rightarrow r}w_{jr} z_j\)
CART per la classificazione
Alberi di classificazione.
Non si cerca di costruire un albero con una variabile quantitativa che assume solo due valori numerici 0 e 1, ma con una variabile risposta considerandola come qualitativa.
I CART consentono di modellare con una funzione a gradini la probabilità di essere in una classe date le \(X\)
\(p(x)=\mathbb{P}\left \{ Y=1 \vert X=x \right \}\)
Si approssima la funzione nel seguente modo:
\(\hat{p}(x)=\sum_{j=1}^J P_j I(x\in R_j)\)
con \(P_j \in (0,1)\) probabilità che \(Y=1\) per la regione \(R_j\), stimati da:
\(\hat{P}_j=M(y_i : x_i \in R_j)=\frac{1}{n_j}\sum_{i\in R_j}I(y_i=1)\) frequenza relativa degli \(1\) nella regione, cioè la media delle \(Y\) dentro il rettangolo (la frequenza relativa è la media perché la variabile è 0 1).
Gli alberi hanno diversi aspetti positivi, tra cui la velocità, ignorano variabili ridondanti, considarano i missing come categoria a parte e piccoli alberi sono facili da interpretare. Però spesso hanno capacità predittive povere principalmente perché le curve di separazione sono parallele agli assi. Se idealmente il gruppo si divide perfettamente da una funzione a cerchio, utilizzare dei rettangoli comporta una perdita sempre più grande all’aumentare delle dimensioni.
Crescita
La creazione dei rettangoli (crescità) verranno definiti in modo analogo agli alberi di regressione, a step successivi si divide il rettangolo, in modo miopico, scegliendo lo split che porta il maggiore decremento della Deviance (per un modello logistico, con la log verosimiglianza bernoulliana - spesso il termine Deviance indica la misura di discrepanza per qualsiasi distribuzione mentre la devianza è il numeratore della varianza):
\(D=-2\sum_{i=1}^n y_i \log{\hat{p}_i}+(1-y_i)\log{(1-\hat{p}_i)}\) si può riscrivere nella forma
\(D=\sum_{j=1}^J -2n_j \left [\hat{P}_j \log{\hat{P}_j}+(1-\hat{P}_j)\log{(1-\hat{P}_j)}\right ]=\sum_{j=1}^J D_j\)
somma delle Deviance dei \(J\) rettangoli.
Per facilitare la generalizzazione a \(k>2\) classi si può riscrivere la Deviance nel seguente modo
\(D=-2n \sum_{j=1}^J \frac{n_j}{n} \sum_{k=0,1} \hat{P}_{jk} \log{\hat{P}_{jk}}=2n \sum_{j=1}^J \frac{n_j}{n} Q(\hat{P}_j)\)
con \(Q(P_j)=-\sum_{k=0,1} P_{jk} \log{P_{jk}}\) entropia di Shannon (indice di impurità di una variabile qualitativa), quindi la devianza complessiva è una media pesata delle impurità dentro i nodi - entropia e log verosimiglianza binomiale sono fortemente legate.
Cross-entropia: opposto della log verosimiglianza binomiale
Ulteriori misure di impurità:
- Indice di Gini (≈ Entropia via serie di Taylor/Mc Laurin): \(Q(P_j)=\sum_{k=0,1} P_{jk}(1-P_{jk})\)
- Indice \(X^2\) di Pearson (Alberi CHAID)
Potatura
Negli alberi di regressione si usa l’insieme di stima per la crescita e quello di verifica per la potatura. Qui per la potatura si usano i casi erroneamente classificati.
Bayes Classifier
Lo scopo dei modelli di classificazione è quello di approssimare la frontiera decisionale di Bayes (Bayes Decision Boundary).
Il classificatore di Bayes è il modello con il minore tasso di errata classificazione.
Ensemble methods
Combinazione di modelli.
Stacking
Si costruisce la previsione usando la media della previsione dei \(M\) modelli differenti, pesando maggiormente i modelli che hanno un errore più basso nel dataset di stima.
\(f_{\mbox{comb}}(x,y)=\sum_{m=1}^M w_m f_m (x,y)\)
Non tiene conto della complessità del modello, quindi rischia il sovra adattamento.
Si può usare la CV-LOO per risolvere: si fa la regressione di ciascuna \(y_i\) sulle previsioni degli \(M\) modelli senza la i-esima osservazione, ottenendo così il valore d’errore da utilizzare come peso nella media.
Funziona bene se i modelli hanno caratteristiche differenti.
Bagging
Breiman, 1996. Bagging o bootstrap aggregation.
Effettua delle medie sulle previsioni, o voto di maggioranza, ottenute sui campioni bootstrap (campionamento con reinserimento).
Consente di rendere più stabile metodi come gli alberi, perdendo la capacità interpretativa.
La varianza della media aritmetica è inversamente proporzionale alla numerosità, quindi comporta una riduzione della varianza.
Con alberi profondi si ha poca distorsione ed elevata varianza, ma la media del Bagging di modelli indipendenti (il ricampionamento produce indipendenza ma i dati sono sempre quelli quindi i modelli non sono completamente indipendenti) riduce la varianza per la legge dei grandi numeri mantenendo la distorsione.
Bumping
Ricerca del modello stocastica.
Una stima per ogni campione bootstrap e si sceglie di aggregare in modo diverso dalla media. Si può ad esempio prendere l’albero che prevede meglio, risultando così interpretabile.
Non ha la qualità del Bagging perché perde la capacità di riduzione della varianza.
Out-of-bag
OBB. Utilizzando i campioni bootstrap sull’insieme di stima, ogni estrazione comporta l’esclusione di un insieme di osservazioni, definito out-of-bag, questo può essere usato come insieme di verifica.
Random Forest
Breiman, 1999.
Come il Bagging ma si campionano anche le variabili. Diventa più veloce il processo di stima. Ad ogni split degli albero si seleziona un numero casuale \(F\) di variabili (solitamente un numero costante), quindi l’albero dovrà scegliere tra un sottoinsieme di variabili. La scelta di \(F\) può essere fatta affinché si minimizzi l’errore sull’insieme di verifica o anche l’errore su OOB.
Un altro parametro di regolazione da definire è il numero di alberi \(B\), l’errore decresce al numero di alberi, quindi sarà un numero sufficientemente alto.
Ciascun albero ha senso farlo crescere e poi la media farà diminuire la varianza.
La scelta di campionare anche le variabili, comporta una maggiore vicinanza all’indipendenza, riducendo la correlazione tra le variabili e quindi la riduzione della varianza è maggiore del Bagging.
Variable Importance
Importanza delle variabili.
Si fanno crescere tutti i \(B\) alberi e si valuta l’errore su OBB. Successivamente si calcolano \(J\) (numero di variabili) errori sull’OOB, permutando di volta in volta la j-esima variabile. Successivamente si calcola la media standardizzata delle differenze tra errori di previsione tra l’insieme non permutato e quello permutato, così ottenendo una misura di quanto una variabile influenza le previsioni.
Ristimare il modello, escludendo una variabile alla volta per valutarne l’impatto con una misura di errore, non è un buon approccio per valutare l’importanza delle variabili. Non si misura il vero effetto sulla previsione togliendo una specifica variabile, perché se si ristima il modello senza quella variabile, le altre variabili (correlate con quella che si toglie), potrebbero entrare nel modello e sostituire l’informazione della variabile tolta, non consentendo di definire quanto è importante la variabile. Quindi è importante che si tiene la previsione ottenuta con la stima su tutti i dati e solo in fase di previsione si utilizza una permutazione delle osservazioni.
Il livello di importanza di una variabile esplicativa non ha una relazione monotona con la previsione della target, una variabile importante può essere un potente predittore di casi positivi a determinati livelli delle altre variabili esplicative, ed essere un potente predittore di casi negativi ad altri livelli delle altre variabili esplicative.
Boosting
Come il bagging ma i campioni bootstrap non sono estratti casualmente ma si ha più probabilità di riestrarre osservazioni mal classificate.
Inizialmente ogni osservazione ha probabilità di estrazione pari a \(p_i=1/N\). All’iterazione \(t\), si ha un tasso di errore \(e_t\) e il parametro \(\beta_t=e_t/(1-e_t)\) servirà per aggiornare i pesi da utilizzare nell’iterazione successiva \(p_i\leftarrow p_i \cdot \beta_t\).
Al momento di aggregarli, non sarà una semplice media aritmetica perché bisogna dare maggiore influenza ai modelli (alberi in questo caso) che sbagliano di meno, pertanto le classificazioni hanno un peso pari a \(\log{(1/\beta_t)}\).
La caratteristica del boosting di concentrarsi sugli errori è un approccio vincente anche se si utilizzano modelli differenti e non solo alberi.
Funziona bene con alberi piccoli (stump è un weak learner, albero con due nodi-foglia), bisognerà fare più passi ma l’operazione di aggiornamento porta una buona previsione. Alberi ad un solo livello potrebbero potrebbero portare l’esclusione della valutazione delle interazioni, a due livelli può risultare migliore.
Il grafico dell’andamento dell’errore contro il numero di iterazioni permette di capire qual è il numero ideale di iterazione a cui fermarsi.
Diversamente dagli altri metodi di combinazioni di modelli, il Boosting non è semplice da utilizzare nel contesto di regressione perché non è facile definire una previsione giusta da una sbagliata.
AdaBoost
Freund & Shapire, 1997.
Algoritmo originale di boosting, non campiona casualmente le osservazioni ad ogni passo, ma pesa diversamente le osservazioni.
Optimal Separating Hyperplanes
Caso perfettamente separato. Vapnik, 1996.
Il metodo è alla base della costruzione delle Support Vector Machine (SVM).
Per i problemi che seguono la target dicotomica è più facile modellarla con la codifica \(+1\) e \(-1\).
Si cerca un iperpiano nello spazio delle \(X\) che riesca a separare in modo ottimale i vari gruppi (nel caso \(p=2\) dividere i più dai meno).
La retta migliore è quella che rende massima la distanza tra i punti più vicini dei due gruppi distinti.
Per identificare la retta, si costruiscono le due rette frontiere parallele (utilizzando 3 punti: con i 2 punti di un gruppo più vicini all’altro gruppo si costruisce la prima frontiera e poi la seconda è tangente al punto più vicino dell’altro gruppo; il gruppo da cui scegliere i 2 punti è quello che genera la banda più grande), la retta migliore è quella a cui viene associata una banda più grande possibile.
Sia \(\beta_0+\vec{x}^{\,T}\vec{\beta}=0\) con \(\vec{x}\in\mathbb{R}^p\) l’equazione che individua un generico iperpiano candidato a separare le due classi, con \(\vec{\beta}\) a norma unitaria.
Un’osservazione \((\tilde{x},y)\) sarà classificata correttamente se
\(y(\beta_0+\tilde{x}^T\beta)>0\) con \(y\in\{-1,1\}\)
\(y(\beta_0+\tilde{x}^T\beta)>1/2\) con \(y\in\{0,1\}\)
nel caso \(\{-1,1\}\) quindi l’osservazione è classificata bene se di segno concorde con l’iperpiano.
L’obiettivo è quindi massimizzare la semi-ampiezza della banda \(M\) vincolata
\(\max\limits_{\beta_0, \beta}{M}\) con i vincoli
\(\begin{cases}
\vert\vert \beta \vert\vert = 1, \\
y_i (\beta_0+\tilde{x}_i^T \beta) \ge M
\end{cases}\) con \(i=1,...,n\)
Osservazione: il problema ha una struttura analoga a molti altri contesti. Se si è interessati a due quantità, di cui una è la più importante (classificare bene) e l’altra meno (trovare la distanza massima), la parte più importante viene vincolata e l’altra massimizzata. Ad esempio, nei test statistici, l’errore di primo tipo si fissa (vincola) (es. \(\alpha=0.5\)), e si massimizza la potenza.
Il problema (grazie a ????) si può ridurre a
\(y_i (\beta_0+\tilde{x}_i^T \beta) \ge M \vert\vert \beta \vert\vert\)
Dunque si pone \(\vert\vert \beta \vert\vert=1/M\) e la funzione obiettivo risulta
\(\min\limits_{\beta_0, \beta}{\vert\vert \beta \vert\vert}\) con il vincolo \(y_i (\beta_0+\tilde{x}_i^T \beta) \ge 1\) con \(i=1,...,n\)
siccome \(\vert\vert \beta \vert\vert\) è difficile da minimizzare perché non è un problema convesso, si può elevare al quadrato e moltiplicare per \(1/2\) mantenendo lo stesso ottimo (il migliore \(\beta\) da trovare rimane invariato, mentre la funzione obiettivo potrebbe portare a valori differenti) e consentendo di risolvere il problema mediante metodi di ottimizzazione quadratica vincolata con disequazioni lineari, ad esempio usando i moltiplicatori di Lagrange.
Determinazione dell’ottimo
\(\min\limits_{\beta_0, \beta}{\frac{1}{2}\vert\vert \beta \vert\vert^2}\) con il vincolo \(y_i (\beta_0+\tilde{x}_i^T \beta) \ge 1\)
Questo problema di minimo vincolato è definito Problema Primale, per risolverlo facilmente bisogna passare alla formulazione Duale.
La teoria dell’ottimizzazione afferma che:
- un problema di ottimizzazione possiede una forma duale (più semplice da risolvere) se la funzione di costo e i vincoli sono strettamente convessi
- se le condizioni in 1 sono soddisfatte, l’ottimo per il problema duale coincide con l’ottimo del problema primale.
Nel caso attuale, la funzione di costo \(\frac{1}{2}\vert\vert \beta \vert\vert^2\) è una parabola (parabole e rette definiscono insiemi convessi), pertanto soddisfa le condizioni del punto 1.
Nel problema primale si ha \(\vert\vert \beta \vert\vert^2\) funzione convessa con un minimo, nel problema duale la funzione si trasforma in concava il cui massimo coincide con il minimo di \(\vert\vert \beta \vert\vert^2\).
La soluzione dalla Lagrangiana risulterà che è un punto di sella.
Grazie a alle condizioni di Khun-Tucker (generalizzazione del metodo dei moltiplicatori di Lagrange con vincoli di disuguaglianza), si ottiene il Problema Duale:
\(\min\limits_{\alpha}\sum_{i=1}^n \alpha_i-\frac{1}{2} \sum_{i=1}^n \sum_{k=1}^n \alpha_i \alpha_k y_i y_k x_i^T x_k\) con il vincolo \(\alpha_i \ge 0\) e \(\sum_{i=1}^n y_i \alpha_i = 0\)
L’iperpiano ottimale separatore genera una funzione \(\hat{f}(x)=x^T\hat{\beta}+\hat{\beta}_0\) per classificare le nuove osservazioni: \(\hat{G}(x)=\mbox{sign}\left \{\hat{f}(x)\right \}= \begin{cases} +1 & \mbox{se }\hat{f}(x) > 0 \\ -1 & \mbox{se }\hat{f}(x) < 0 \\ \mbox{a caso} & \mbox{se }\hat{f}(x) = 0 \end{cases}\)
I coefficienti \(\hat{\beta}\) che risolvono il problema sono una combinazione lineare dei punti di supporto (support points) \(x_i\) (punti sulla frontiera). I vettori per cui \(\alpha_i>0\) sono detti vettori di supporto (support vectors).
\(\beta=\sum_{i=1}^n \alpha_i y_i x_i \qquad \hat{\beta}=\sum_{i\in S} \alpha_i x_i\) con \(S\) insieme dei vettori di supporto.

Support Vector Classifier
Estensione del caso precedente ma in una situazione non perfettamente separabile, con la costruzione di soft-margin (margini morbidi).
Si introducono le variabili ausiliarie (slack variable) \(\xi=(\xi_1,...,\xi_n)\) che misurano la distanza tra il punto classificato male (perché si trova nell’altra metà) e la frontiera del suo gruppo (quella più lontana), i punti classificati bene hanno \(\xi_i=0\).
L’errore totale lo si vorrà inferiore di una costante \(\sum_{i=1}^n \xi_i \le B\).
Si riscrive il problema precedente di minimo con l’aggiunta delle variabili ausiliarie:
\(\max\limits_{\beta_0, \beta}{\frac{1}{2}\vert\vert\beta\vert\vert^2 + C \sum_{i=1}^n\xi_i}\) con i vincoli
\(\begin{cases}
y_i (\beta_0+\tilde{x}_i^T \beta) \ge 1-\xi_i, \forall i \\
\xi_i \ge 0
\end{cases}\)
dove \(C\) costante positiva (inverso alla costante \(B\)), parametro di regolazione e costo di violazione delle barriere (più \(C\) è grande, maggiore è l’importanza di non superare i vincoli e le bande saranno più strette).
Il problema duale ha come vincoli \(0\le \alpha_i \le C\) e \(\sum_{i=1}^n \alpha_i y_i =0\).
La soluzione di ottimo è \(\hat{\beta}=\sum_{i=1}^n a_i y_i \tilde{x}_i\)
le \(a_i\) sono diverse da \(0\) solo per i punti che sono nel vettore di supporto (support vector). Prima nel caso di gruppi completamente separati, nell’insieme di supporto era composto solo da punti sulle barriere, qui l’insieme di supporto è composto dai sia dai punti sulle barriere che dai punti per i quali \(\xi_i>0\).
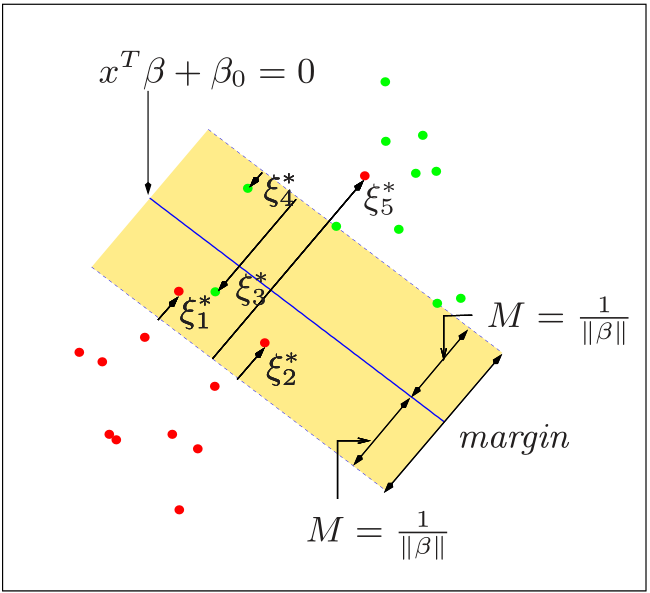
I punti (o vettori) di supporto (\(\alpha_i >0\)) sono i punti neri cerchiati (\(\xi_i=0,\alpha_i>0\)), più i punti blu all’interno del rettangolo (porzione di piano) blu e i punti gialli all’interno del rettangolo giallo (\(\xi_i>0,\alpha_i>0\)).
Support Vector Machine
SVM. Macchine basate sui vettori di supporto.
L’approccio precedente considera un iperpiano rispetto le \(x\), ora si considera rispetto \(h(x)\), trasformazioni delle variabili esplicative, così da generare funzioni separatrici non lineari.
\(f(x)=h(x)^T\beta+\beta_0=\sum_{i=1}^n a_i y_i \left \langle h(x), h(x_i) \right \rangle + \beta_0\)
L’equazione di stima dipenderà dalle \(x\) solo dal prodotto vettoriale
\(\hat{f}(x)=\sum_{i=1}^n a_i y_i h(x)^T h(\tilde{x}_i)+\hat{\beta_0}\)
con \(\tilde{x}_i\) di supporto e \(x\) su cui fare la previsione.
Il parametro di regolazione \(C\) (più è piccolo e più la curva è smooth), può essere ottenuto via CV (es. CV 10 gruppi, con \(C\) sequenza di 25 valori logaritmicamente equispaziati tra \(10^{-2}\) e \(10^4\)).
Le SVM funzionano bene anche quando il numero di variabili è molto superiore al numero di osservazioni e il fatto che l’ottimizzazione si basa solo su alcuni punti è anche computazionalmente vantaggioso. Quindi non dipende dai \(p\) parametri \(\beta\) ma dagli \(\vert S \vert \le n\) parametri \(a_i\) diversi da zero.
Le SVM sono sensibili a variabili che confondono la relazione con la target, non avviene una selezione delle variabili.
Kernel
Si definisce funzione nucleo (kernel)
\(K(x,x')=\left \langle h(x), h(x') \right \rangle\)
che calcola i prodotti interni nello spazio delle variabili trasformate.
I parametri dei kernel conviene fissarli, dipende dalla variabilità del nucleo, la CV già la si usa per l’identificazione di altri parametri.
Kernel Polinomiale
\(K(x,x_i)=(1+ \left \langle x, x_i \right \rangle)^d\)
Se \(p\) numero di variabili e \(d\) grado del polinomio crescono, diventa uno spazio enorme ma che non sarà tutto esplorato perché sarà valorizzato solo sui vettori di supporto.
\(\hat{f}(x)=\sum_{i=1}^n \hat{a}_i y_i K(x,x_i)+\hat{\beta}_0\)
Con \(p=2\) e \(x=(x_1,x_2)\):
\(K(x,x') =
(1 + \left \langle x, x' \right \rangle)^2 =
(1 + x_1 x_1' + x_2 x_2')^2 =\)
\(1 + (x_1 x_1')^2 + (x_2 x_2')^2 + 2 x_1 x_1' + 2 x_2 x_2' + 2 x_1 x_1' x_2 x_2'=*\)
Si determina facilmente che le 6 funzioni \(h(x)\) il cui prodotto interno restituisce quel kernel sono:
\(* = \begin{pmatrix}
1 & \sqrt{2}x_1 & \sqrt{2}x_2 & x_1^2 & x_2^2 & \sqrt{2}x_1x_2
\end{pmatrix}
\begin{pmatrix}
1 \\
\sqrt{2}x_1' \\
\sqrt{2}x_2' \\
x_1'^2 \\
x_2'^2 \\
\sqrt{2}x_1'x_2'
\end{pmatrix}\)
Kernel Base radiale
Radial basis kernel, RBF kernel
\(K(x,x')=\exp{(-\gamma \vert\vert x-x' \vert\vert ^2)}\)
La base implicita \(h(x)\) per un nucleo radiale è in teoria di dimensione infinita.
I punti neri sono il supporto della frontiera lineare nello spazio trasformato.
I margini (curve tratteggiate) e le frontiere di decisione (linee continue) che sono lineari (rette) nello spazio trasformato diventano curve non-lineari nello spazio originale.
Da determinare le \(h(x)\) con \(\gamma=1\)
Kernel Sigmoidale
Neural network kernel
\(K(x,x')=\tanh{(\kappa_1 \left \langle x, x' \right \rangle + \kappa_2)}\)
Da determinare le \(h(x)\) con \(\kappa_1=1, \kappa_2=0\)
SVM come metodo di penalizzazione
Con \(f(x)=h(x)^T \beta+\beta_0\)
si può considerare il seguente problema di ottimizzazione
\(\min\limits_{\beta_0, \beta}{\sum_{i=1}^n [1-y_i f(x_i)]_+ + \frac{1}{C} \vert\vert \beta \vert\vert ^2}\)
con \(+\) a pedice indica la parte positiva
\(L(y,f)=[1-y_i f(x_i)]_+\) è la hinge loss e penalizza i margini negativi che rappresentano le errate classificazioni
\(\frac{1}{C} \vert\vert \beta \vert\vert ^2\) termine di penalizzazione per la hinge loss (che modificato come il LASSO può essere utilizzato per la selezione delle variabili)

Stima intervallare per modelli di regressione
La previsione intervallare è una misura di variabilità della singola stima.
Si cercano delle bande di previsione valide anche per i dati di verifica.
La parte di rappresentazione grafica delle bande viene meno per un numero elevato di variabili, ma consente comunque di avere informazioni utili sulla variabilità della previsione con un limite inferiore e superiore.
Sia \((x_i,y_i)\overset{\text{iid}}{\sim}P\) l’insieme di dati, data una nuova osservazione \(x_{n+1}\) si cerca una regione (intervallo) \(A(x)\subseteq \mathbb{R}\) che contenga il dato nuovo \(y_{n+1}\) con una certa probabilità fissata
\(\mathbb{P}(y_{n+1}\in A(x)\vert x_{n+1}=x)\ge 1-\alpha\) con \(\alpha \in (0,1)\)
ovvero un insieme di valori altamente probabili condizionatamente a quel valore di \(x_{n+1}\).
(nota: come il p-value, è più agevole considerare la disuguaglianza come un’uguaglianza)
La probabilità che l’intervallo contenga \(y_{n+1}\) è \(1-\alpha\)
\(A(x)\) è ignota e la si stima dai dati \(A(x,D=(x_i,y_i)_{i=1}^n)\), quindi
\(\mathbb{P}(y_{n+1}\in A(x;D)\vert x_{n+1}=x)\) in media sarà \(\ge 1-\alpha\) con \(\alpha \in (0,1)\)
La probabilità non è più soltanto rispetto alla \(y_{n+1}\), ma rispetto a tutti i possibili valori ottenuti campionando la regione (analogia con gli intervalli di confidenza).
Un intervallo di confidenza quantifica la variabilità della stima \(\hat{f}(x)\), che sotto valide assunzioni va a coincidere con il vero valore di \(f(x)\).
Un intervallo di previsione quantifica la variabilità associata ad una futura osservazione \(y_{n+1}\), anche con infiniti dati si avra sempre un po’ di variabilità causata dal processo generatore dei dati, variabilità del termine d’errore, quindi sono generalmente più grandi, ma godono di caratteristiche teoriche simili agli intervalli di confidenza.
Per costruire gli intervalli di previsione si segue una logica analoga agli intervalli di confidenza in cui si cerca una quantità pivotale con distribuzione nota.
Distribuzione nota
Con \(P\) nota la funzione di ripartizione è nota e la funzione quantile condizionata di livello \(\alpha\) è un buon candidato per la stima intervallare
\(F(y\vert x)=\mathbb{P}(y_{n+1}\vert x_{n+1}=x)\Rightarrow q_\alpha (x)=\mbox{inf}\{y\in\mathbb{R}:F(y\vert x)\ge \alpha\}\)
allora \(A(x)=[q_{\alpha/2}(x),q_{1-\alpha/2}(x)]\) e per costruzione la probabilità è pari a \(1-\alpha\)
Modello lineare nei parametri
Intervallo esatto: normale con parametri noti
\(y_i=x_i^T\beta+\epsilon_i \Rightarrow y_{n+1}\vert x_{n+1}=x \overset{\text{iid}}{\sim}\mathcal{N}(x^T\beta_{\small{noto}},\sigma^2_{\small{noto}})\)
allora l’intervallo di previsione è \(A(x)=x^T\beta\pm\sigma^2 z_{1-\alpha/2}\) con \(z_\alpha\) quantile di una normale,
ed è facile verificare che la probabilità è \(1-\alpha\).
Non si cerca di quantificare l’incertezza solo rispetto la distribuzione (che in questo caso ha parametri noti), ma anche rispetto a \(y_{n+1}\) il nuovo valore di \(y\) che non è stato osservato.
Intervallo approssimato: normale con parametri stimati
Sia \(\hat{\beta}\) la stima ai minimi quadrati e \(s^2\) stima non distorta di \(\sigma^2\), ottenute sui dati \(D=(x_i,y_i)_{i=1}^n\)
allora \(A(x)=x^T\hat{\beta}\pm s^2 z_{1-\alpha/2}\), ma l’intervallo sarà approssimativamente \(1-\alpha\)
Intervallo esatto: normale con parametri stimati
Sia \(\mbox{var}(y_{n+1}-x^T\hat{\beta})=\mbox{var}(y_{n+1})+\mbox{var}(x^T\hat{\beta})=\sigma^2+\sigma^2x^T(X^TX)^{-1}x\)
(nota: \(y_{n+1}\) e \(\hat{\beta}\) sono indipendenti perché quest’ultimo dipende dai primi \(n\) dati)
Si dimostra che \(\frac{y_{n+1}-x^T\hat{\beta}}{s(x)}\sim t_{n-p} \qquad s^2(x)=s^2+s^2x^T(X^TX)^{-1}x\)
allora \(A(x;D)=x^T\hat{\beta}\pm s^2 (x) t_{1-\alpha/2,n-p}\) ha esattamente probabilità \(1-\alpha\) (intesa anche con i valori \(D\) che ha usato per effettuare la stima ai minimi quadrati)
Qui si tiene conto della variabilità dei parametri, ottenendo un’ampiezza più ampia.
Le assunzioni di normalità, omoschedasticità e la scelta del modello di regressione, se non valide/ben specificate comportano un livello di copertura empirico sui dati di verifica più ampio del livello dichiarato.
Approccio non parametrico
Intervallo approssimato: normale con parametri stimati
Sia \(y_i=f(x_i)+\epsilon_i \quad\) con \(\epsilon_i\overset{\text{iid}}{\sim}\mathcal{N}(0,\sigma^2)\)
Si assume (sperando nel tlc) che \(\frac{y_{n+1}-\hat{f}(x)-b(x)}{s(x)}\overset{\text{approx}}{\sim}\mathcal{N}(0,1) \qquad s^2(x)=var\left \{ y_{n+1} - \hat{f}(x)-b(x) \right \}=\sigma^2+\mbox{var}\left \{ \hat{f}(x) \right \}\)
dove \(b(x)=\mathbb{E}\left \{ \hat{f}(x) - f(x) \right \}\) è la distorsione, \(\sigma^2\) varianza residuale ineliminabile del modello e \(\mbox{var}\left \{ \hat{f}(x) \right \}\) varianza dello stimatore
Ipotizzando che la distorsione sia nulla,
allora \(A(x;D)=\hat{f}(x)\pm s^2(x) z_{1-\alpha/2}\)
inoltre, bisogna ottenere una stima della varianza residuale \(\sigma^2\) (dentro \(s^2\)) e la varianza dello stimatore (es. con bootstrap o ipotizzarla nulla se si ha \(n\) grande).
Lisciatori lineari
Stimatore non parametrico lisciatore lineare
\(\hat{f}(x)=\sum_{i=1}^n \ell_i (x) y_i\)
si ha che \(\mbox{var}\left \{ \hat{f}(x) \right \}=\sum_{i=1}^n \ell_i^2(x) \mbox{var}(y_i)=\sigma^2 \sum_{i=1}^n \ell_i^2(x)\)
per stimare la varianza residuale \(\sigma^2\), si può calcolare la varianza residuale nell’insieme di verifica o fare una stima corretta sull’insieme di stima:
\(\sigma^2=\frac{1}{n-p^*} \sum_{i=1}^n \left \{ y_i - \hat{f}(x_i) \right \} ^2\)
con \(p^*=2 \mbox{tr}(L)-\mbox{tr}(L^T L)\approx p\) gradi di libertà equivalenti e \(L\) matrice di lisciamento associata a \(\hat{f}(x)\)
Sebbene non ci siano assunzioni sulla \(f(x)\) l’intervallo di previsione potrebbe avere una copertura empirica più grande di quella prefissata causato da una non validità della normalità degli errori, l’omoschedasticità e/o la relazione additiva degli errori alla funzione.
Si cerca quindi un approccio che permetta di annullare le assunzioni e consenta di gestire stimatori più complessi. Questo non è possibile a meno di intervalli degenere a dimensione infinita (Lei and Wasserman, 2014). Una soluzione è passare da una copertura condizionale (per ogni \(x\)) ad una marginale (marginalmente rispetto a \(x\)).
Regione di previsione marginale - Conformal Inference
\(A(x;D)\) garantisce una copertura marginale di livello \(1-\alpha\) se per tutte le distribuzioni di \(P\) e per ogni \(x\in\mathbb{R}\), assumendo unicamente che i dati siano scambiabili (o iid per semplicità)
allora \(\mathbb{P}(y_{n+1}\in A(x_{n+1};D))\ge 1-\alpha\)
la probabilità intesa rispetto a \((x_i,y_i)_{i=1}^n\) e la coppia \((x_{n+1},y_{n+1})\)
(nota: la probabilità a \(1-\alpha\) non è solo di \(y_{n+1}\) che appartiene alla regione ma è anche legata alla generazione di quest’ultima).
Si impone che gli intervalli siano centrati sulla previsione \(\hat{f}(x)\) per migliorare l’interpretazione.
Quindi si cercano intervalli \(A(x;D)=\hat{f}(x)\pm \Delta \quad \mbox{t.c.} \quad \mathbb{P}(y_{n+1}\in A(x_{n+1};D))\ge 1-\alpha\),
con \(\Delta\) più piccolo possibile mantenendo la validità
Split conformal
Si dividono in due parti i dati \(n_{\small\mbox{stima}}\) e \(n_{\small\mbox{verifica}}\),
dall’insieme di stima si ottiene \(\hat{f}(x)\) e dall’insieme di verifica i residui \(\vert e_i \vert=\vert y_i - \hat{f}(x_i) \vert\) per \(i=1,...,n_{\small\mbox{verifica}}\).
Sia \(k=(n_{\small\mbox{verifica}}+1)(1-\alpha)\)
si pone \(\Delta=\) il k-esimo più piccolo elemento tra i residui, cioè quantità molto simile al quantile empirico dei residui dell’insieme di verifica (evitando così l’overfitting).
Quindi \(A_{\mbox{split}}(x;D)=\hat{f}(x)\pm \Delta\)
allora \(\mathbb{P}(y_{n+1}\in A_{\mbox{split}}(x_{n+1};D))\ge 1-\alpha\)
inoltre \(\mathbb{P}(y_{n+1}\in A_{\mbox{split}}(x_{n+1};D))\le 1-\alpha+\frac{1}{n_{\small\mbox{verifica}}+1}\)
Funziona bene anche con \(n\) piccoli, non ci sono approssimazioni né assunzioni.
I quantili empirici sono uno stimatore non parametrico di una parte della distribuzione ??
Se viene utilizzato in questo modo l’insieme di verifica non può essere usato per l’identificazione di parametri di regolazione o altri scopi.
Anche se il modello è impreciso, la probabilità di copertura empirica rimane valida.
Locally weighted split conformal
Per modellare meglio la variabilità delle bande (soprattutto in caso di eteroschedasticità), si può agire a livello condizionale, mantenendo la cupertura marginale valida.
Si ripetono gli step iniziali dello split conformal e successivamente si stima un secondo modello sull’insieme di stima per calcolare la previsone dei residui in valore assoluto \(\hat{p}(x)=\vert y-\hat{f}(x) \vert\)
Sull’insieme di verifica si ottengono i residui standardizzati \(\vert e_i^* \vert = \vert e_i \vert / \hat{p}(x_i)\)
Si pone \(\Delta=\) il k-esimo più piccolo elemento tra i residui standardizzati e \(\Delta (x)=\hat{p}(x) \Delta\)
Varianti
- Full Conformal: non usa divisione stima verifica, ma stima il modello \(n\) volte, non produce intervalli ma regioni anche sconnesse
- Variante divisione datati in \(K\) parti (analogo a CV)
- Jacknife+: divisione analoga alla CV-LOO
Regressione quantile
Come accennato un buon modo per costruire regioni di previsione consiste basarsi sui quantili condizionati
\(A(x)=[q_{\alpha/2}(x),q_{1-\alpha/2}(x)]\)
si cercano di stimare direttamente i due quantili con la regressione quantile, per \(n\) elevato, se la stima è affidabile, la copertura è \(1-\alpha\)
\(\hat{f}(x)\) è una stima per la media condizionata, si cerca di stimare la funzione di perdita quadratica, minimizzata per \(n\) grande dalla media condizionata. La funzione che minimizza la funzione di perdita degli scarti in valore assoluto è la mediana, estendibile ai quantili condizionati.
La funzione di perdità per stimare i quantili sarà
\(\sum_{i_1}^n m_{\alpha} \{ y_i , f(x_i) \}\)
dove \(m_{\alpha}(y,\hat{y})=\begin{cases}
\alpha (y-\hat{y}) & \mbox{se } y>\hat{y} \\
(1-\alpha)(y-\hat{y}) & \mbox{altrimenti}
\end{cases}\)
con \(f(x_i)\) funzione più o meno complessa come il modello lineare, quindi stimando i quantili condizionati sotto l’ipotesi che seguano un modello lineare, ma va risolto il problema di ottimizzazione in modo numerico.
Sono coperture valide sia a livello marginale che condizionale, ma quest’ultimo valido solo con la condizione per \(n\rightarrow \infty\). Ma diversamente dallo split conformal in cui si ha il un metodo di previsione e lo si modifica per ottenere gli intervalli di previsione, questo approccio necessita di algoritmi numerici appositi.
Calcolo Parallelo
Limiti fisici: CPU, RAM, I/O disco, trasferimento
Limiti operazionali: algoritmi sequenziali, iterativi (minimi quadrati ricorsivi, newton raphson, backfitting, …)
Ostacoli: communication overhead (la complessità di gestire le interazioni tra i cores) e load balance (bilanciamento tra i task nei vari cores)
Embarrassingly parallel problem: è quando la parallelizzazione può avvenire in modo perfetto (es. somma delle colonne di una tabella, ogni colonna può essere gestita da un core in modo indipendente)
Approcci alla parallelizzazione
Data parallelism
Map-Reduce: si divide il dataset in \(k\) chunk di dimensione \(n_k=n/k\), ogni parte viene associata ad un diverso core (mapping) e poi un core eseguirà l’operazione di aggregazione (reduce - si può dedicare un core appositamente per questa operazione).
Minimi Quadrati “parallelizzati’’:
sia \(y_i=\beta_0 +\beta_1 x_i +\epsilon_i\)
bisogna calcolare \(\hat{\beta}_1=\frac{\mbox{Cov}(x,y)}{\mbox{Var}(x)}\) e \(\hat{\beta}_0=\frac{1}{n}\sum_{i=1}^n y_i - \hat{\beta}_1 \frac{1}{n}\sum_{i=1}^n x_i\)
La covarianza (e varianza) si può esprimere come
\(\mbox{Cov}(x,y)=\frac{1}{k}\sum_{j=1}^k \left ( \frac{1}{n_j}\sum_{i=1}^{n_j}x_i^{(j)} y_i^{(j)} \right )-
\left [ \frac{1}{k}\sum_{j=1}^k \left ( \frac{1}{n_j}\sum_{i=1}^{n_j}x_i^{(j)} \right ) \right ] \cdot
\left [ \frac{1}{k}\sum_{j=1}^k \left ( \frac{1}{n_j}\sum_{i=1}^{n_j}y_i^{(j)} \right ) \right ]\)
con \((x^{(j)},y^{(j)})\) sottoporzione \(j\)-esima del dataset, \(j=1,...,k\)
Model parallelism
L’algoritmo contiene operazioni non sequenziali tra loro, separabili in \(k\) parti, ogni parte viene associata a un diverso core e poi si aggregano (es. CV).
Operation parallelism
Eseguire operazioni algebriche (es. prodotti, inversioni e scomposizione di matrici) in parallelo. Parallelizzazione implicita.
R
library
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# Best subset regression
leaps::
# Stepwise regression
MASS::stepAIC
stats::step
# LARS
lars::
biglars::
# LASSO pathwise
glmnet::
# Local regression
sm::sm.regression
KernSmooth::locpoly
# LOESS
stats::loess
stats::loess.smooth
stats::scatter.smooth
# Regression splines
splines::
# Smoothing splines
smooth.splines::
# MARS
polspline::polymars
mda::mars
earth::earth
# GAM
gam::gam
mgcv::gam
# PPR
stats::ppr
# CART
tree::
rpart::
# NN
nnet::
neuralnet::
AMORE::
# DeepLearning:
Keras::
h2o::
Utili
Risorse
- Data analysis and data mining
- The Elements of Statistical Learing ESLII
- An Introduction to Statistical Learning ISLR